背景
Redis 在源码中大量使用 sds(Simple Dynamic String)而不是传统的 char* 字符串,是为了避免 C 字符串的性能和安全问题
C 字符串(null-terminated string)具有以下缺陷:
- 无法感知自身长度:每次调用
strlen都是一次 O(n) 操作 - 二进制不安全:
\0被当作字符串结束符,导致字符串中不能包含 NULL 字节 - 扩容与内存泄露风险高:无统一管理策略,容易导致 buffer overflow 或内存浪费
- 不支持预分配或惰性缩容:每次修改都可能频繁 realloc,开销较大
| 问题点 | 描述 |
|---|---|
| 内存管理繁琐 | 需要手动 malloc + realloc + free |
| 易出错 | strcpy、strcat 容易越界 |
| 低性能 | strlen(s) 每次都是 O(N),不像 sdslen() 是 O(1) |
没有 free 字段 |
不能预留扩展空间,只能每次 realloc |
| 不可二进制安全 | C 字符串不能存有 \0 中间字节,sds 是 binary-safe |
| 特性 | sds 优势 |
|---|---|
| 自动管理容量 | 有 alloc 和 free |
| 拼接安全 | sdscat 自动扩容 |
| 长度 O(1) | sdslen(s) 读取 header |
| 可存二进制 | 可存 \0,不会截断 |
| 内存对齐良好 | 更少碎片,性能优 |
sds 与 char * 比较示例
sds
sds s = sdsnew("hello");
s = sdscat(s, " world");
printf("%s\n", s); // hello world
printf("%d\n", sdslen(s)); // 11
等效 char* 实现,须手动 malloc、realloc、strcat,容易出错且效率低
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
// 模拟 sdsnew("hello")
char *s = (char *)malloc(6); // "hello" + '\0'
if (!s) {
perror("malloc failed");
return 1;
}
strcpy(s, "hello");
// 模拟 sdscat(s, " world")
const char *to_append = " world";
size_t old_len = strlen(s);
size_t add_len = strlen(to_append);
size_t new_len = old_len + add_len;
char *tmp = (char *)realloc(s, new_len + 1); // +1 for '\0'
if (!tmp) {
free(s); // 避免内存泄漏
perror("realloc failed");
return 1;
}
s = tmp;
strcat(s, to_append);
printf("%s\n", s); // 输出 hello world
printf("%lu\n", strlen(s)); // 输出 11,O(N)
free(s); // 手动释放
return 0;
}\0 结束字符对字符串长度的影响
#include <stdio.h>
#include <string.h>
int main() {
char *a = "red\0is";
char *b = "redis\0";
printf("%lu\n", strlen(a));
printf("%lu\n", strlen(b));
return 0;
}字符串操作函数复杂度
-
strlen
需要遍历字符数组中的每一个字符,才能得到字符串长度,复杂度 O(N)
-
strcat
char *strcat(char *dest, const char *src) {
//将目标字符串复制给tmp变量
char *tmp = dest;
//用一个while循环遍历目标字符串,直到遇到“\0”跳出循环,指向目标字符串的末尾
while(*dest)
dest++;
//将源字符串中的每个字符逐一赋值到目标字符串中,直到遇到结束字符
while((*dest++ = *src++) != '\0' )
return tmp;
}遍历字符串才能得到目标字符串的末尾
还要再遍历源字符串才能完成追加
调用 strcat 时还需要确认目标字符串具有足够的可用空间,不然就需要手动分配空间,从而增加了编程的复杂度。复杂度增加,影响字符串操作效率
设计解读
sds 实际上就是一个结构体包裹的字符串,结构体中包含了:
- 字符串长度(
len) - 分配空间长度(
alloc) - 字符数组本身
最初的 sds 结构(<3.2)
struct sdshdr {
int len; // 实际字符串长度
int free; // 剩余可用空间
char buf[]; // 字符数组
};基于此设计实现了:
- O(1) 获取字符串长度
- 支持二进制数据(可包含
\0) - 惰性内存释放、预分配空间优化
sdshdr5~64
redis 3.2 之后,原始的单一结构被更精细化的多结构方案取代,以进一步压缩内存空间,特别是对大量小 key 的优化非常明显
Redis 性能工程优化的典型例子:从朴素设计到类型分级微调,逐步走向极致内存利用和性能兼顾
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 sds strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
MSB(Most Significant Bit):最高有效位 /LSB(Least Significant Bit):最低有效位。例,8位二进制数11001010中,最左边的1就是MSB,最右边的0就是LSB能通过 buf 数组向低地址偏移一个字节来获取 flags 字段的值
buf是一个柔性数组成员,不占用结构体自身的空间
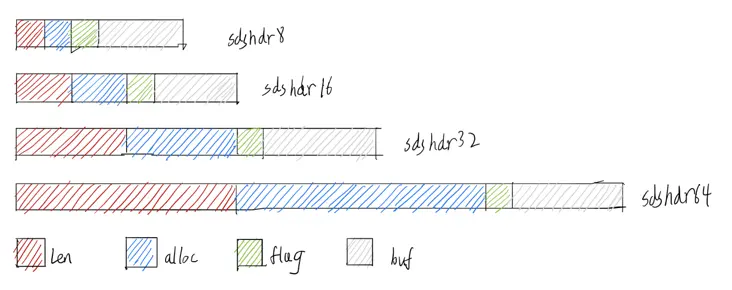
| 类型 | 长度字段类型 | 长度字段长度 | 适合长度范围 | 结构名 |
|---|---|---|---|---|
sdshdr5 |
无结构体 | 0~31 字节(5 bit) | 无结构体,仅 flags | |
sdshdr8 |
uint8_t |
1 | 0~255 字节 | sdshdr8 |
sdshdr16 |
uint16_t |
2 | 0~65535 字节 | sdshdr16 |
sdshdr32 |
uint32_t |
4 | 0~4GB | sdshdr32 |
sdshdr64 |
uint64_t |
8 | >4GB | sdshdr64 |
static inline unsigned char sdsType(const sds s) {
unsigned char flags = s[-1];
return flags & SDS_TYPE_MASK;
}
static inline size_t sdslen(const sds s) {
switch (sdsType(s)) {
case SDS_TYPE_5: return SDS_TYPE_5_LEN(s);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}每种 sdshdr 结构体都包含一个 flags 字段,用于标识该 sds 使用的是哪种结构类型
其中,flags 字段的 低 3 位 用于存储类型信息;而 sdshdr5 是个特殊的情况,它的 flags 字段的 高 5 位 还用于直接存储字符串长度
为了提取并判断 sds 的类型,Redis 使用 sds_TYPE_MASK 屏蔽掉 flags 字段的高 5 位,仅保留低 3 位进行类型比较
具体用途如下:
s[-1]表示通过sds指针偏移,取出了对应的flags字段SDS_TYPE_5_LEN(flags)提取sdshdr5的flags字段高 5 位,获取字符串长度sdsType(s)提取flags字段的低 3 位,判断该sds实例属于哪种sdshdr类型- 通过
flags & sds_TYPE_MASK得到类型后,程序再转换为对应结构体类型以访问其字段
为了节省内存空间,sds 在保存小字符串时使用更紧凑的结构(如 sdshdr5),这体现了典型的以空间换时间的设计思想,使得在减少堆分配开销的同时仍能高效处理字符串操作
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4这些宏定义了 SDS 的 5 种类型,数字代表用于存储字符串长度的位数:
TYPE_5:特殊类型,长度存储在 flag 的高 5 位TYPE_8:长度用 8 位(1字节)存储TYPE_16:长度用 16 位(2字节)存储TYPE_32:长度用 32 位(4字节)存储TYPE_64:长度用 64 位(8字节)存储
sds5 的特殊设计
sds5 是专门针对短字符串(<= 31 字节)优化的:
- 不使用显式 header
- 低 3 位(bits 0-2):存储 类型标识(
SDS_TYPE_5是0) - 高 5 位(bits 3-7):存储 字符串长度(最大支持
2^5 - 1 = 31)
类型相关宏
#define SDS_TYPE_MASK 7 // 二进制 00000111
#define SDS_TYPE_BITS 3SDS_TYPE_MASK:用于提取 flags 的低 3 位(类型信息)SDS_TYPE_BITS:表示类型占用的位数(3位可以表示 0-7,足够覆盖 5 种类型)
关键操作宏
◉ SDS_TYPE_5_LEN
#define SDS_TYPE_5_LEN(s) (((unsigned char)(s[-1])) >> SDS_TYPE_BITS)- 用于获取
TYPE_5类型的字符串长度 - 操作方式:
- 取
s[-1](flags 字节) - 右移 3 位(丢弃低 3 位的类型信息)
- 剩下的高 5 位就是长度值
- 取
◉ SDS_HDR 和 SDS_HDR_VAR
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))这两个宏用于获取 SDS 的 header 指针:
SDS_HDR_VAR:声明一个变量sh指向 headerSDS_HDR:直接返回 header 指针
工作原理:
s是字符串数据部分的指针sizeof(struct sdshdr##T)是 header 的大小s - header_size得到 header 的起始地址
◉ 以 sdslen("hello") 为例
-
获取类型
flags = s[-1]; // flags 字节(00101000) type = flags & SDS_TYPE_MASK; // 00101000 & 00000111 00101000 & 00000111 ----------- 00000000 -
获取长度
#define SDS_TYPE_5_LEN(s) (((unsigned char)(s[-1])) >> SDS_TYPE_BITS) len = SDS_TYPE_5_LEN(s); s[-1] 是 flags 字节(00101000) SDS_TYPE_BITS = 3,所以 flags >> 3 得到高5位的长度值 00101000 >> 3= 00000101 (5)
sdsnewlen 逻辑
典型函数:
sdsnewlen(const void *init, size_t initlen)这是创建一个 sds 的底层核心函数,几乎所有其他创建函数(如 sdsnew、sdsempty)最终都调用它
在创建新字符串时,Redis 使用 sdsnewlen 函数,它会根据初始化字符串的长度,选择合适的 sdshdr 类型
-
选择合适的 header 类型
通过
sdsReqType(initlen)根据字符串长度选择最小可用的sdshdr类型(如sdshdr5,sdshdr8等) -
计算内存大小并分配
使用
sdsHdrSize(type)获取对应 header 的大小,整个结构的分配大小为:hdrlen(header)+ initlen(实际内容)+ 1(结尾的 \0)然后用
s_malloc从堆中分配一整块内存 -
设置 sds 指针
分配到的内存首部是
sdshdr,sds类型变量s实际上是char*,它指向 header 之后的buf[]区域:s = (char*)sh + hdrlen -
复制字符串内容并补零
如果传入了初始内容
init,使用memcpy拷贝到s指向的区域,并在末尾追加一个\0,确保兼容 C 字符串函数 -
初始化 header 中的元信息
对于非
sdshdr5类型,通过宏sds_HDR_VAR(type, s)获取 header 指针,并设置:-
len为字符串长度 -
alloc为分配空间长度(不含\0)
而
sdshdr5类型较特殊,它将长度信息编码在flags的高 5 位,因此不使用显式的len和alloc字段 -
sds sdsnewlen(const void *init, size_t initlen) {
void *sh; // 指向 header
sds s; // 返回的 sds 实际是 buf 指针
char type = sdsReqType(initlen); // 选择合适的 sdshdr 类型
size_t hdrlen = sdsHdrSize(type); // 计算 header 大小
size_t totlen = hdrlen + initlen + 1; // 总长度 = header + buf + '\0'
sh = s_malloc(totlen); // ⬅️ 从堆上分配内存(重点)
if (!sh) return NULL;
s = (char*)sh + hdrlen; // sds 指向 buf 区域
if (initlen && init) {
memcpy(s, init, initlen); // 拷贝初始字符串
}
s[initlen] = '\0'; // 保证兼容 C 字符串
sds_HDR_VAR(type, s)->len = initlen;
sds_HDR_VAR(type, s)->alloc = initlen;
// sds_TYPE_5 不存 len/alloc,用位域编码
return s;
}flowchart TD
A["调用 sdsnewlen(init, initlen)"] --> B["调用 _sdsnewlen(init, initlen, 0)"]
B --> C["计算 type = sdsReqType(initlen)"]
C --> D{type == SDS_TYPE_5 且 initlen == 0?}
D -- 是 --> E[type = SDS_TYPE_8]
D -- 否 --> F[保持 type 不变]
E --> G["计算 hdrlen = sdsHdrSize(type)"]
F --> G
G --> H["分配内存: sh = s_malloc_usable(hdrlen+initlen+1, &bufsize)"]
H --> I{sh == NULL?}
I -- 是 --> J[返回 NULL]
I -- 否 --> K["adjustTypeIfNeeded(&type, &hdrlen, bufsize)"]
K --> L["调用 sdsnewplacement(sh, bufsize, type, init, initlen)"]
L --> M[初始化头部和数据]
M --> N[返回 sds 指针]
sds 操作效率
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}- 获取目标字符串的当前长度,并调用 sdsMakeRoomFor 保证其有足够的空间接收追加的字符串
- 在保证了目标字符串的空间足够后,将源字符串中指定长度 len 的数据追加到目标字符串
- 最后,设置目标字符串的最新长度
sds 已存字符数组的使用长度和分配空间大小,避免了对字符串的遍历操作,降低了操作开销,(创建、追加、复制、比较等)更高效
把目标字符串的空间检查和扩容封装在了 sdsMakeRoomFor 函数中,涉及字符串空间变化的操作中,如追加、复制等,会直接调用该函数,避免开发人员因忘记给目标字符串扩容,而导致操作失败(如内存溢出)的情况
__attribute__((packed)) 编译优化
64 位系统编译器默认按 8 字节对齐方式分配内存
struct s1 {
char a;
int b;
} ts1;
printf("%lu\n", sizeof(ts1)); // output : 8
char 占 1 字节,int 占 4 字节,但打印结果是 8
编译器给 s1 结构体对齐后,分配的是 8 个字节的空间
Redis 用__attribute__((packed)) 属性定义结构体,结构体实际占用多少内存空间,编译器以 紧凑模式 就分配多少空间,结构体成员不做内存对齐优化
struct __attribute__((packed)) s2{
char a;
int b;
} ts2;
printf("%lu\n", sizeof(ts2)); // output : 5
以sdshdr32为例:
- len、alloc 为 uint32_t 类型 ,各占4字节
- flags 为 unsigned char类型,占1字节
- buf是一个柔性数组成员,不占用结构体自身的空间
未使用__attribute__((__packed__))属性时,编译器对结构体进行字节对齐,通常按成员中占用空间最大的基本数据类型进行对齐
可能会在flags成员后填充3个字节,以保证下一个成员buf从合适的位置开始,总大小12字节(4 + 4 + 1 + 3字节填充)
使用__attribute__((__packed__))属性后,结构体取消字节对齐,不自动添加填充字节。sdshdr32结构体大小只需计算成员变量本身的大小,即4(len)+ 4(alloc)+ 1(flags),共9字节,相比未使用packed属性节省3字节内存空间
大规模使用动态字符串时,可以显著减少内存的使用量,提升Redis的性能和效率
查看结构体大小和成员偏移(地址)
#include <stdio.h>
#include"sds.h"
int main(){
printf("%zu\n", sizeof(struct sdshdr5));
printf("%zu\n", sizeof(struct sdshdr8));
printf("%zu\n", sizeof(struct sdshdr16));
printf("%zu\n", sizeof(struct sdshdr32));
printf("%zu\n", sizeof(struct sdshdr64));
printf("Offset of len: %zu\n", (size_t)&(((struct sdshdr32*)0)->len));
printf("Offset of alloc: %zu\n", (size_t)&(((struct sdshdr32*)0)->alloc));
printf("Offset of flags: %zu\n", (size_t)&(((struct sdshdr32*)0)->flags));
printf("Offset of buf: %zu\n", (size_t)&(((struct sdshdr32*)0)->buf));
return 0;
}(size_t)&(((struct sdshdr32*)0)->len)步骤解析
-
(struct sdshdr32*)0将0强制转换为一个指向结构体的指针。这个指针本质上是无效的空指针(不能解引用),但它语法上合法地表示“结构体起始位置” -
(((struct sdshdr32*)0)->len)取这个结构体中
len成员的值(或者准确说,是它的“位置”) 因为指针是空(地址 0),所以这表达式其实相当于:从结构体起始地址 0 偏移到 len 成员
-
&(((struct sdshdr32*)0)->len)
取出
len成员的地址,但因为这是以0为基址,所以这个地址其实就是len在结构体中的偏移量 -
(size_t)
把地址转换为整数(偏移量值),这样就可以用来打印或者比较了
兼容 c string
sds同样遵循 C 字符串以 \0 结尾, \0 的 1 字节不计算在len 属性里
遵循 \0 结尾的好处是, sds 可以直接重用一部分 C 字符串函数库函数
sds指针 s ,可以直接使用 stdio.h/printf 函数
printf("%s", s->buf);C 字符串作为字符串字面量(string literal), 用在一些无须对字符串值进行修改的地方, 比如打印日志
sds 扩容 sdsMakeRoomFor
C 语言字符串不记录自身的长度,如strcat 去 append要重分配,忘了会缓冲区溢出;trim要重分配,忘了会内存泄露
sds 的空间分配策略杜绝了发生缓冲区溢出的可能性: sds API先检查空间, 不够,自动扩展,使用 sds 不需要手动修改 sds 空间大小, 也不会缓冲区溢出
sds 实现了空间预分配和惰性空间释放优化策略
| 阶段 | 说明 |
|---|---|
| 小字符串 | 每次扩容为所需空间的 2 倍,避免频繁 realloc |
| 大字符串 | 超过 1MB 后,每次 固定增加 1MB(避免过度增长) |
| 总是多预留 | 保证拼接后还有 free 空间,用于下次避免 realloc |
sds 动态扩容采用 指数增长 + 预留空间 策略,初期快速增长,后期平稳增长,确保高性能字符串操作,广泛用于 Redis 各处
流程
flowchart TD
A[开始: _sdsMakeRoomFor] --> B[获取当前可用空间 avail]
B --> C{avail >= addlen?}
C -->|是| D[直接返回 s]
C -->|否| E[计算当前长度 len 和头部指针 sh]
E --> F[计算基本需求: reqlen = len + addlen]
F --> G{检查 size_t 溢出}
G -->|溢出| H[断言失败]
G -->|正常| I{greedy == 1?}
I -->|是| J[贪婪模式: 预分配更多空间]
I -->|否| K[精确模式: 只分配需要的空间]
J --> L{newlen < SDS_MAX_PREALLOC?}
L -->|是| M[newlen *= 2]
L -->|否| N[newlen += SDS_MAX_PREALLOC]
K --> O[newlen = reqlen]
M --> P[确定 SDS 类型: type = sdsReqType]
N --> P
O --> P
P --> Q{type == SDS_TYPE_5?}
Q -->|是| R[type = SDS_TYPE_8]
Q -->|否| S[保持当前类型]
R --> T[计算新头部长度 hdrlen]
S --> T
T --> U[检查 size_t 溢出]
U --> V{oldtype == type?}
V -->|是| W[可以使用 realloc]
V -->|否| X[必须使用 malloc]
W --> Y[调用 s_realloc_usable]
Y --> Z{realloc 成功?}
Z -->|否| AA[返回 NULL]
Z -->|是| BB[更新字符串指针 s]
BB --> CC{需要调整类型?}
CC -->|是| DD[移动字符串数据]
CC -->|否| EE[跳过数据移动]
DD --> FF[更新 SDS 头部信息]
EE --> FF
X --> GG[调用 s_malloc_usable]
GG --> HH{malloc 成功?}
HH -->|否| AA
HH -->|是| II[调整类型如果需要]
II --> JJ[复制字符串数据到新位置]
JJ --> KK[释放旧内存]
KK --> LL[更新字符串指针 s]
LL --> MM[更新 SDS 头部信息]
FF --> NN[计算实际可用空间 usable]
MM --> NN
NN --> OO[设置分配大小 sdssetalloc]
OO --> PP[返回新的 SDS 指针]
D --> QQ[结束]
PP --> QQ
AA --> QQ
H --> QQ
style A fill:#e1f5fe
style QQ fill:#c8e6c9
style AA fill:#ffcdd2
style H fill:#ffcdd2
style W fill:#fff3e0
style X fill:#f3e5f5
greedy
sds _sdsMakeRoomFor(sds s, size_t addlen, int greedy)
sds sdsMakeRoomFor(sds s, size_t addlen) {
return _sdsMakeRoomFor(s, addlen, 1);
}
/* Unlike sdsMakeRoomFor(), this one just grows to the necessary size. */
sds sdsMakeRoomForNonGreedy(sds s, size_t addlen) {
return _sdsMakeRoomFor(s, addlen, 0);
}greedy 参数控制 SDS 字符串在扩容时的内存分配策略,它决定了是否进行预分配(preallocation)
if (greedy == 1) {
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
}两种策略
-
Greedy 模式 (greedy = 1)
-
当新长度 < 1MB: 将新长度翻倍 (newlen *= 2)
-
当新长度 ≥ 1MB: 额外分配 1MB 空间 (newlen += SDS_MAX_PREALLOC)
-
-
Non-Greedy 模式 (greedy = 0)
- 只分配恰好需要的空间 (newlen = len + addlen)
Greedy 模式的优势:
-
减少内存重分配次数:通过预分配更多空间,避免频繁的 realloc 调用
-
提高性能:特别是在字符串频繁追加操作的场景下
-
空间换时间:用更多内存换取更好的性能
Non-Greedy 模式的优势:
-
内存效率:只分配必要的空间,节省内存
-
适合一次性操作:当不需要频繁追加时使用
使用场景
-
sdsMakeRoomFor (greedy=1): 用于需要频繁追加字符串的场景
-
sdsMakeRoomForNonGreedy (greedy=0): 用于一次性操作或内存敏感的场景
这种设计体现了 Redis 在性能和内存使用之间的平衡考虑
◉ Greedy
场景一:字符串频繁追加操作
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}- 原因:字符串追加操作通常需要多次执行,使用 greedy 模式可以预分配更多空间,减少后续的内存重分配
场景二:网络缓冲区扩展networking.c
c->querybuf = sdsMakeRoomFor(c->querybuf, readlen);- 原因:网络读取缓冲区需要频繁扩展,greedy 模式可以避免频繁的 realloc 调用
场景三:协议构建tracking.c
proto = sdsMakeRoomFor(proto,count*15);- 原因:构建 Redis 协议响应时,通常会进行多次字符串操作,预分配空间可以提高性能
◉ Non-Greedy
场景一:精确的查询缓冲区扩展
c->querybuf = sdsMakeRoomForNonGreedy(c->querybuf,ll+2-querybuf_len);- 原因:当知道确切需要多少空间时,避免过度分配内存
场景二:网络读取的精确分配
c->querybuf = sdsMakeRoomForNonGreedy(c->querybuf, readlen);◉ 决策逻辑分析举例
上面两个场景二即使都是"已知长度",但根据具体的业务场景和性能需求,Redis 选择了不同的分配策略!
常量定义
#define PROTO_IOBUF_LEN (1024*16) /* 16KB - 通用I/O缓冲区大小 */
#define PROTO_MBULK_BIG_ARG (1024*32) /* 32KB - 大参数阈值 */ if (!(c->flags & CLIENT_MASTER) && // master client's querybuf can grow greedy.
(big_arg || sdsalloc(c->querybuf) < PROTO_IOBUF_LEN)) {
/* When reading a BIG_ARG we won't be reading more than that one arg
* into the query buffer, so we don't need to pre-allocate more than we
* need, so using the non-greedy growing. For an initial allocation of
* the query buffer, we also don't wanna use the greedy growth, in order
* to avoid collision with the RESIZE_THRESHOLD mechanism. */
c->querybuf = sdsMakeRoomForNonGreedy(c->querybuf, readlen);-
使用 sdsMakeRoomForNonGreedy 的情况
使用 Non-Greedy 的条件:
-
非主客户端 (!(c->flags & CLIENT_MASTER))
-
且满足以下任一条件:
- big_arg = 1:正在读取大参数(≥32KB)
- sdsalloc(c->querybuf) < PROTO_IOBUF_LEN:当前缓冲区小于16KB
-
-
使用 sdsMakeRoomFor 的情况
} else { c->querybuf = sdsMakeRoomFor(c->querybuf, readlen);使用 Greedy 的条件:
-
主客户端 (c->flags & CLIENT_MASTER)
-
或者:非大参数且缓冲区已足够大(≥16KB)
-
源码
sdsnew
1. 函数调用链
sdsnew("hello")
↓
sdsnewlen("hello", 5) // 计算字符串长度
↓
_sdsnewlen("hello", 5, 0) // 核心创建逻辑
↓
sdsnewplacement(...) // 在分配的内存上构造SDS
2. 核心逻辑步骤
步骤1:确定SDS类型 (sdsReqType)
char type = sdsReqType(initlen);根据字符串长度选择最合适的SDS类型:
-
SDS_TYPE_5: 长度 < 32 (1«5)
-
SDS_TYPE_8: 长度 ≤ 255 - 头部大小 - 1
-
SDS_TYPE_16: 长度 ≤ 65535 - 头部大小 - 1
-
SDS_TYPE_32: 长度 ≤ 2^32 - 头部大小 - 1
-
SDS_TYPE_64: 长度 > 2^32 - 头部大小 - 1
步骤2:特殊处理空字符串
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;空字符串通常是为了后续追加,SDS_TYPE_5 不适合追加操作,所以升级到 SDS_TYPE_8
步骤3:计算头部长度并分配内存
int hdrlen = sdsHdrSize(type);
sh = s_malloc_usable(hdrlen+initlen+1, &bufsize);-
计算对应类型的头部大小
-
分配内存:头部 + 数据 + 结束符(’\0')
-
bufsize 是实际分配到的内存大小(可能比请求的大)
步骤4:调整类型(如果需要)
adjustTypeIfNeeded(&type, &hdrlen, bufsize);如果分配器返回的内存比预期大,可能需要升级SDS类型以充分利用内存
步骤5:构造SDS结构 (sdsnewplacement)
return sdsnewplacement(sh, bufsize, type, init, initlen);3. sdsnewplacement 详细逻辑
3.1 计算指针位置
int hdrlen = sdsHdrSize(type);
size_t usable = bufsize - hdrlen - 1;
sds s = buf + hdrlen; // 数据区指针
unsigned char *fp = ((unsigned char *)s) - 1; // flags指针
3.2 根据类型初始化头部
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS); // 类型和长度编码在1字节
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen; // 设置长度
sh->alloc = usable; // 设置分配大小
*fp = type; // 设置类型
break;
}
// ... 其他类型类似
}3.3 初始化数据区
if (init == SDS_NOINIT)
init = NULL;
else if (!init)
memset(s, 0, initlen); // 清零
else if (initlen)
memcpy(s, init, initlen); // 拷贝初始数据
s[initlen] = '\0'; // 添加结束符
4. 内存布局示例
+--------+--------+--------+--------+--------+--------+--------+ | flags | 'h' | 'e' | 'l' | 'l' | 'o' | '\0' | +--------+--------+--------+--------+--------+--------+--------+ ^ ^ sh s 地址: sh sh+1 sh+2 sh+3 sh+4 sh+5 sh+6 内容: 0x28 0x68 0x65 0x6C 0x6C 0x6F 0x00 含义: flags 'h' 'e' 'l' 'l' 'o' '\0'
5. 返回结果
返回指向数据区起始位置的指针 s,用户可以直接当作字符串使用,但SDS内部知道如何通过 s-1 访问头部信息
sdsnewlen & sdstrynewlen
sds sdsnewlen(const void *init, size_t initlen) {
return _sdsnewlen(init, initlen, 0);
}
sds sdstrynewlen(const void *init, size_t initlen) {
return _sdsnewlen(init, initlen, 1);
}trymalloc 参数的作用:用于控制内存分配失败时的行为
-
sdsnewlen:使用 trymalloc = 0,分配失败时会终止程序
-
sdstrynewlen:使用 trymalloc = 1,分配失败时返回 NULL
- 内存分配策略选择
sds _sdsnewlen(const void *init, size_t initlen, int trymalloc) {
void *sh;
char type = sdsReqType(initlen);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type);
size_t bufsize;
assert(initlen + hdrlen + 1 > initlen); /* Catch size_t overflow */
sh = trymalloc?
s_trymalloc_usable(hdrlen+initlen+1, &bufsize) :
s_malloc_usable(hdrlen+initlen+1, &bufsize);- 两种分配模式
-
trymalloc = 0:使用 s_malloc_usable (即 zmalloc_usable)
-
如果内存分配失败,会调用 zmalloc_oom_handler 函数
-
默认情况下会打印错误信息并调用 abort() 终止程序
-
适用于必须成功分配内存的场景
-
-
trymalloc = 1:使用 s_trymalloc_usable (即 ztrymalloc_usable)
-
如果内存分配失败,返回 NULL
-
不会终止程序,允许调用者处理分配失败的情况
-
适用于可以容忍分配失败的场景
-
- 使用场景
-
sdsnewlen:用于必须成功创建字符串的场景,如果内存不足程序会终止
-
sdstrynewlen:用于可以容忍分配失败的场景,调用者需要检查返回值是否为 NULL
提供两种不同的内存分配策略,以适应不同的使用场景和错误处理需求
SDS_NOINIT
是一个特殊的标记常量,用于告诉 sdsnewlen() 函数 不要初始化 buf[] 内容,即不拷贝、不清零、直接分配即可
适用于直接分配空间但不初始化内容,随后立刻用新数据写满的场景
举几个典型例子:
-
src/config.c
sds config = sdsnewlen(SDS_NOINIT, sb.st_size); if (rioRead(rf, config, sb.st_size) == 0) { sdsfree(config); // 错误处理... }读取配置文件内容,先分配一块未初始化的 SDS 空间,然后直接把文件内容读入这块空间
-
src/networking.c
c->querybuf = sdsnewlen(SDS_NOINIT, c->bulklen+2); if (rioRead(rdb, c->querybuf, c->bulklen+2) == 0) { sdsfree(c->querybuf); // 错误处理... }网络模块接收客户端大批量数据时,先分配一块未初始化的 SDS 缓冲区,随后直接读取网络数据填充
-
src/aof.c
argsds = sdsnewlen(SDS_NOINIT, len); if (rioRead(rdb, argsds, len) == 0) { sdsfree(argsds); // 错误处理... }AOF(追加文件)重放时,分配未初始化的 SDS,然后直接读取数据写入
这些用法的共同点是:分配内存后,马上用外部数据(如文件、网络、序列化数据等)完全覆盖,不需要初始化内容,以提升性能
sdsresize
flowchart TD
A["开始: sdsResize(s, size, would_regrow)"] --> B[获取当前SDS信息]
B --> C["oldtype = sdsType(s)"]
B --> D["oldhdrlen = sdsHdrSize(oldtype)"]
B --> E["len = sdslen(s)"]
B --> F[sh = s - oldhdrlen]
C --> G{检查是否需要调整}
D --> G
E --> G
F --> G
G{"sdsalloc(s) == size?"} -->|是| H[直接返回s]
G -->|否| I[处理长度截断]
I{size < len?} -->|是| J[len = size]
I -->|否| K[计算新的SDS类型]
J --> K
K --> L["type = sdsReqType(size)"]
L --> M{would_regrow == 1?}
M -->|是| N{type == SDS_TYPE_5?}
N -->|是| O[type = SDS_TYPE_8]
N -->|否| P[计算新头部长度]
M -->|否| P
O --> P
P --> Q["hdrlen = sdsHdrSize(type)"]
Q --> R[判断是否使用realloc]
R --> S{use_realloc = oldtype==type OR
type < oldtype AND type > SDS_TYPE_8?}
S -->|是| T[使用realloc路径]
S -->|否| U[使用malloc路径]
T --> V[newlen = oldhdrlen + size + 1]
U --> W[newlen = hdrlen + size + 1]
V --> X{是否启用Jemalloc?}
W --> Y["newsh = s_malloc_usable(newlen, &bufsize)"]
X -->|是| Z[检查是否已最优分配]
X -->|否| AA[执行realloc]
Z --> BB["bufsize = sdsAllocSize(s)"]
BB --> CC["alloc_already_optimal = je_nallocx(newlen, 0) == bufsize"]
CC --> DD{alloc_already_optimal?}
DD -->|是| EE[跳过realloc]
DD -->|否| AA
AA --> FF["newsh = s_realloc_usable(sh, newlen, &bufsize)"]
FF --> GG{newsh == NULL?}
GG -->|是| HH[返回NULL]
GG -->|否| II[更新指针]
II --> JJ[s = newsh + oldhdrlen]
JJ --> KK{需要调整类型?}
KK -->|是| LL[调整类型并移动数据]
KK -->|否| MM[计算newsize]
LL --> NN[memmove数据]
NN --> OO[更新类型和长度]
OO --> MM
MM --> PP[newsize = bufsize - oldhdrlen - 1]
PP --> QQ[断言检查]
Y --> RR{newsh == NULL?}
RR -->|是| HH
RR -->|否| SS[调整类型]
SS --> TT["adjustTypeIfNeeded(&type, &hdrlen, bufsize)"]
TT --> UU[复制数据]
UU --> VV["memcpy(s, newsh + hdrlen, len + 1)"]
VV --> WW[释放旧内存]
WW --> XX["s_free(sh)"]
XX --> YY[更新指针]
YY --> ZZ[s = newsh + hdrlen]
ZZ --> AAA["s[-1] = type"]
AAA --> BBB[计算newsize]
BBB --> CCC[newsize = bufsize - hdrlen - 1]
CCC --> DDD[断言检查]
EE --> MM
QQ --> EEE[设置结束符]
DDD --> EEE
EEE --> FFF["s[len] = '\0'"]
FFF --> GGG["sdssetlen(s, len)"]
GGG --> HHH["sdssetalloc(s, newsize)"]
HHH --> III[返回s]
H --> JJJ[结束]
HH --> JJJ
III --> JJJ
style A fill:#e1f5fe
style H fill:#c8e6c9
style HH fill:#ffcdd2
style III fill:#c8e6c9
style JJJ fill:#f3e5f5
主要分支
-
快速返回路径
- 如果当前分配大小已经等于目标大小,直接返回
-
长度处理
- 如果目标大小小于当前长度,进行截断
-
类型计算
- 根据目标大小计算合适的 SDS 类型
- 如果预期会再次增长,避免使用 SDS_TYPE_5
-
分配策略选择
- realloc 路径:类型相同或可以安全降级时使用
- malloc 路径:需要改变头部类型时使用
-
Jemalloc 优化
- 检查是否已经是最优分配,避免不必要的 realloc 调用
-
内存操作
- 根据选择的路径执行相应的内存分配和复制操作
- 处理类型调整和断言检查
-
最终设置
-
设置结束符、长度和分配大小
-
返回调整后的 SDS 字符串
-
常见调用模式
-
would_regrow = 1:预期字符串会再次增长,避免使用 SDS_TYPE_5
-
would_regrow = 0:不预期再次增长,可以使用更小的头部类型
-
size = sdslen(s):移除空闲空间
-
size > sdslen(s):预分配空间
-
size < sdslen(s):裁剪数据
主要调用方分析
1. SDS 库内部调用
sds sdsRemoveFreeSpace(sds s, int would_regrow) {
return sdsResize(s, sdslen(s), would_regrow);
}用途:
-
移除 SDS 字符串末尾的空闲空间
-
将分配大小调整为实际使用的长度
-
用于内存优化,减少内存占用
调用场景:
-
字符串操作完成后,清理多余空间
-
内存紧张时进行压缩
2. Redis 服务器核心功能
客户端查询缓冲区管理 (server.c)
c->querybuf = sdsResize(c->querybuf, resize, 1);上下文
if (querybuf_size > PROTO_RESIZE_THRESHOLD && querybuf_size/2 > c->querybuf_peak) {
size_t resize = sdslen(c->querybuf);
if (resize < c->querybuf_peak) resize = c->querybuf_peak;
if (c->bulklen != -1 && resize < (size_t)c->bulklen + 2) resize = c->bulklen + 2;
c->querybuf = sdsResize(c->querybuf, resize, 1);
}用途:
-
内存优化:当客户端查询缓冲区过大时进行压缩
-
智能调整:根据历史峰值和当前需求调整大小
-
性能平衡:避免频繁的内存重新分配
关键逻辑:
-
当缓冲区大小超过阈值且大于峰值的一半时触发
-
确保调整后的大小不小于历史峰值
-
考虑批量操作的长度需求
3. HyperLogLog 数据结构
HyperLogLog 稀疏表示优化 (hyperloglog.c)
if (sdsalloc(o->ptr) < server.hll_sparse_max_bytes && sdsavail(o->ptr) < 3) {
size_t newlen = sdslen(o->ptr) + 3;
newlen += min(newlen, 300); /* Greediness */
if (newlen > server.hll_sparse_max_bytes)
newlen = server.hll_sparse_max_bytes;
o->ptr = sdsResize(o->ptr, newlen, 1);
}用途:
-
预分配优化:为 HyperLogLog 稀疏表示预分配空间
-
贪婪策略:根据当前长度动态调整分配大小
-
内存限制:确保不超过稀疏表示的最大字节数
优化策略:
-
当可用空间不足 3 字节时触发
-
采用贪婪增长策略(翻倍或增加 300)
-
限制在稀疏表示的最大范围内
4. 测试代码
SDS 库测试 (sds.c 中的测试函数)
x = sdsResize(x, 200, 1); // 扩展测试
x = sdsResize(x, 80, 1); // 收缩测试
x = sdsResize(x, 30, 1); // 裁剪测试
x = sdsResize(x, 400, 1); // 跨类型扩展测试
x = sdsResize(x, 4, 1); // 跨类型收缩测试
用途:
-
验证 sdsResize 的各种边界情况
-
测试不同类型 SDS 之间的转换
-
确保内存管理的正确性
5. 总结
sdsResize 的主要调用方体现了 Redis 在不同层面的内存优化策略:
-
基础库层面:sdsRemoveFreeSpace 提供通用的内存压缩功能
-
网络层面:客户端缓冲区管理,平衡内存使用和性能
-
数据结构层面:HyperLogLog 的智能预分配策略
-
测试层面:确保功能的正确性和稳定性
这些调用方都充分利用了 sdsResize 的灵活性和 Jemalloc 优化,体现了 Redis 在内存管理方面的深度优化
sdstemplate
// 定义回调函数
static sds myCallback(sds varname, void *arg) {
if (strcmp(varname, "name") == 0) {
return sdsnew("Redis Server");
} else if (strcmp(varname, "version") == 0) {
return sdsnew("7.0.0");
}
return NULL; // 未知变量
}
// 使用模板
const char *template = "Welcome to {name} version {version}";
sds result = sdstemplate(template, myCallback, NULL);
if (result) {
printf("结果: %s\n", result);
sdsfree(result);
}应用场景
Redis 进程标题定制
// 模板: "Redis {title} {listen-addr} {server-mode}"
// 结果: "Redis my-redis-server 127.0.0.1:6379"
日志格式化
// 模板: "[{timestamp}] [{level}] {component}: message"
// 结果: "[2025-07-31 17:54:23] [INFO] MAIN: Redis server started"
配置文件生成
// 模板: "bind {bind}\nport {port}\ncluster-enabled {cluster-enabled}"
// 结果: "bind 0.0.0.0\nport 6380\ncluster-enabled yes"
回调函数模式
简单键值对
static sds simpleCallback(sds varname, void *arg) {
if (strcmp(varname, "key") == 0) {
return sdsnew("value");
}
return NULL;
}动态数据
static sds timeCallback(sds varname, void *arg) {
time_t now = time(NULL);
struct tm *tm_info = localtime(&now);
char buffer[64];
if (strcmp(varname, "timestamp") == 0) {
strftime(buffer, sizeof(buffer), "%Y-%m-%d %H:%M:%S", tm_info);
return sdsnew(buffer);
}
return NULL;
}结构化数据
typedef struct {
char *hostname;
int port;
char *config_file;
} ServerInfo;
static sds serverCallback(sds varname, void *arg) {
ServerInfo *info = (ServerInfo *)arg;
if (strcmp(varname, "hostname") == 0) {
return sdsnew(info->hostname);
} else if (strcmp(varname, "port") == 0) {
char buffer[16];
sprintf(buffer, "%d", info->port);
return sdsnew(buffer);
}
return NULL;
}