堆/栈
-
栈: 函数调用基础(维护函数调用的上下文),大多数编程语言存储
局部变量和函数参数的地方,线程私有自动分配,如函数局部变量 int b;自动在栈中为b开辟空间
-
堆:应用程序动态分配的内存区域,malloc/new,通常是程序的
运行库管理栈空间分配自行申请,并指明大小,如 p1 = (char *)malloc(10);或c++ new 运算符。注意p1本身在栈中
栈或堆现有大小不够用时,按增长方向扩大自身尺寸,直到预留的空间被用完为止
栈扩展,触发由 expand_stack() 在Linux中处理的页面错误,调用acct_stack_growth()检查是否适合扩展堆栈
栈大小低于RLIMIT_STACK(通常8MB),栈增长,如果已经达到最大栈大小,溢出,段错误(Segmentation Fault)
运行库向操作系统 批发 较大的堆空间,然后 零售 给程序用
全部“售完”或程序有大量的内存需求时,再根据实际需求向操作系统 进货
os 内存布局&策略
各 malloc 内存分配管理方式离不开 os 内存布局策略
布局
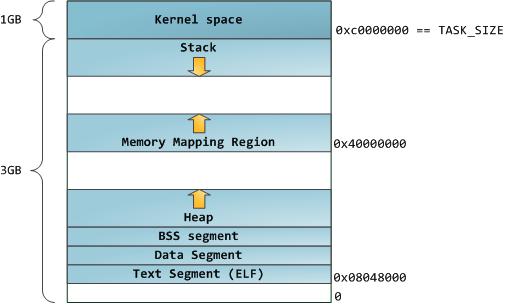
32位经典内存布局
32位默认内存布局
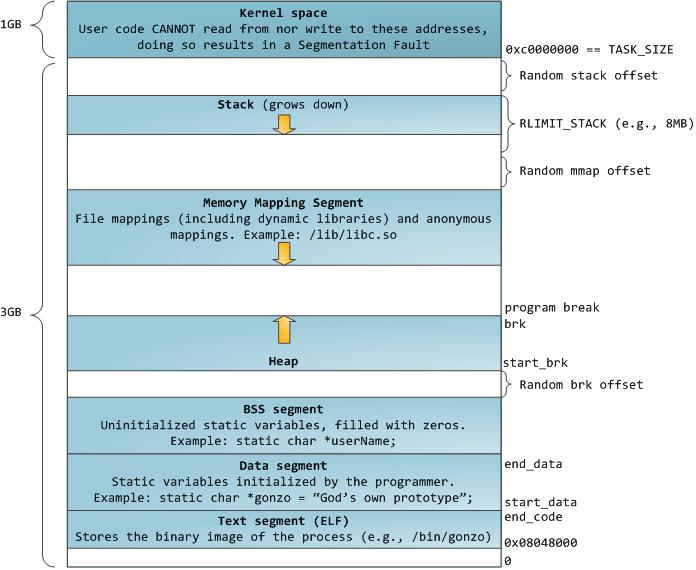
加几种 Random offset,不易受内存溢出攻击
堆仍然向上,但mmap向下增长,os有栈大小限制
64位内存布局

寻址空间大,沿用32位的经典布局,加上随机的mmap起始地址,防止溢出攻击
40TB+内存才把堆内存地址用光
策略
malloc
大内存需求
直接mmap
小内存需求
- brk 扩大堆顶
- os把需要的内存分页映射过来
- 再由这些malloc管理这些堆内存块,减少系统调用
free
free内存时不同由malloc不同策略,不一定会把内存真正地还给系统
所以很多时候,访问free掉的内存,不会立即Run Time Error,只有访问的地址没有对应的内存分页,才会崩掉
系统调用 brk(sbrk)和mmap
brk() 和 sbrk() 扩展heap的上界
#include <unistd.h>
int brk( const void *addr );
void* sbrk ( intptr_t incr );Brk参数为新的brk上界地址,成功返回1,失败返回0
Sbrk参数为申请内存的大小,返回heap新的上界brk的地址
#include <sys/mman.h>
void *mmap(void *addr, size\_t length, int prot, int flags, int fd, off\_t offset);
int munmap(void *addr, size_t length);Mmap 可映射磁盘文件到内存中;或匿名映射,不映射磁盘文件,向映射区申请一块内存 Malloc使用的是mmap的第二种用法(匿名映射)
brk、sbrk、mmap属系统调用,每次申请内存都调用,影响性能
其次,这样申请内存容易产生碎片,因为堆从低地址到高地址,高地址内存没有被释放,低地址的内存就不能被回收
ptmalloc
https://blog.csdn.net/z_ryan/article/details/79950737
main_area/no_main_area
两个area 形成环形链表进行管理
每进程只一个主分配区,允许多个非主分配区
main可用brk和mmap分配,而 no_main只能用mmap映射内存块
Chunk结构
主从分配区模式,线程要分配资源时,从链表找一个没加锁的分配区进行分配
使用中/空闲 chunk数据结构基本项同,但有设计技巧,巧妙的节省了内存
使用中的chunk

chunk管理内存块,bin链表管理大小相似的chunk
空闲chunk

原本用户数据区存储四个指针 fd指向后一个空闲的chunk;bk指向前一个空闲的chunk
通过这两个指针将大小相近的chunk连成一个双向链表
large bin中的空闲chunk还有两个指针,fd_nextsize/bk_nextsize,用于加快在large bin中查找最近匹配的空闲chunk
不同的chunk链表通过bins或者fastbins来组织
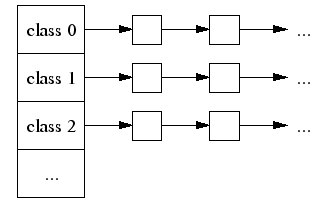
空闲链表bins
避免频繁系统调用,降低内存分配开销
free释放掉的内存,ptmalloc不马上还给OS,被ptmalloc本身的空闲链表bins管理起来,下次malloc时,从空闲bins寻找 将相似大小的chunk用双向链表链接,称bin
ptmalloc维护了128bin。每个bins都维护了大小相近的双向链表的chunk。基于chunk的大小,有下列几种可用bins:
小内存分配
-
small bin 前64 相邻bin里 chunk大小差8字节
-
large bin 先大小,再最近使用的顺序排列,每次分配找一个最小够用chunk
-
A
在主分配区
-
M
mmap出来的
-
P
上一个内存紧邻的chunk是否在使用
free时,检查附近chunk,尝试把连续空闲chunk合并,放到unstored bin
但当很小chunk释放时,并入fast bin
同样 fast bin连续内存块会被合并到一个unsorted bin里,然后再才进入普通bin里
malloc小内存,先查找fast bin,再查找unsorted bin,最后查找普通的bin,如果unsorted bin里的chunk不合适,则会把它扔到bin里
大内存分配
如果前面的bin里的空闲chunk都不足以满足需要,尝试从top chunk里分配内存
top chunk也不够,从OS拿
特别大的内存,直接从系统mmap出来,不受chunk管理,回收时也会munmap还给os
简而言之 : 小内存: [获取分配区(arena)并加锁] -> fast bin -> unsorted bin -> small bin -> large bin -> top chunk -> 扩展堆 大内存: 直接mmap
总结
释放时几乎是和分配反过来,再加上可一些chunk合并和从一个bin转移到另一个bin的操作 并且如果顶部有足够大的空闲chunk,则收缩堆顶并还给os
介于此,对于ptmalloc的内存分配使用有几个注意事项:
默认后分配内存先释放,因为内存回收是从top chunk开始 避免多线程频繁分配和释放内存,会造成频繁加解锁 不要分配长生命周期的内存块,容易造成内碎片,影响内存回收
tcmalloc(thread cache malloc)
ptmalloc性能问题,一般倾向使用三方malloc
- 不同分配区(arena)的内存不能交替使用
- 每个内存块分配都要浪费8字节内存等等
内存管理分为线程内存和中央堆两部分

小内存分配
内部维护几十个不同大小的分配器,和ptmalloc差异是,每个分配器的大小差是不同的,按8字节、16字节、32字节等间隔开
内存分配时找到最小符合条件的,比如833字节到1024字节的内存分配请求都会分配一个1024大小的内存块
如果这些分配器的剩余内存不够了,会向中央堆申请一些内存,打碎以后填入对应分配器中
同样,如果中央堆也没内存了,就向中央内存分配器申请内存
线程缓存内的几十个分配器分别维护了一个大小固定的自由空间链表,直接由这些链表分配内存的时候是不加锁的
但是中央堆是所有线程共享的,在由其分配内存的时候会加自旋锁(spin lock)
线程内存池每次从中央堆申请内存的时候,分配多少内存也直接影响分配性能
申请地太少会导致频繁访问中央堆,也就会频繁加锁,而申请地太多会导致内存浪费
tcmalloc里,这个每次申请的内存量是动态调整的,类似把tcp窗口反过来用的慢启动(slow start)算法调整max_length, 每次申请内存是申请max_length和每个分配器对应的num_objects_to_move中取小的值的个数的内存块
num_objects_to_move取值比较简单,是以64K为基准,并且最小不低于2,最大不高于32的值
也就是说,对于大于等于32K的分配器这个值为2(好像没有这样的分配器 class),对于小于2K的分配器,统一为32
对于max_length就比较复杂了,而且其更多是用于释放内存
max_length由1开始,在其小于num_objects_to_move的时候每次累加1,大于等于的时候累加num_objects_to_move
释放内存的时候,首先max_length会对齐到num_objects_to_move,然后在大于num_objects_to_move的释放次数超过一定阀值,则会按num_objects_to_move缩减大小
大内存分配
大于8个分页, 即32K,tcmalloc直接在中央堆里分配(以分页为单位)
同样按大小维护了256个空闲空间链表,前255个分别是1个分页、2个分页到255个分页的空闲空间,最后一个是更多分页的小的空间。这里的空间如果不够用,就会直接从系统申请了

分页管理 – span
tcmalloc 用span管理内存分页,一个span可以包含几个连续分页
span状态
- 未分配(在空闲链表中)
- 作为大对象分配
- 作为小对象分配(span内记录了小对象的class size)
32位系统中,span分为两级由中央分配器管理。第一级有2^7个节点,第二级是2^13个 32位总共只能有2^20个分页(每个分页4KB = 2^12)
64为系统中,有三级
释放
算分页编号,再找对应span
小对象直接归入小对象分配器的空闲链表。等到空闲空间足够大以后划入中央堆
大对象把物理地址连续的前后的span也找出来,如果空闲则合并,并归入中央堆中
而线程缓存内的分配器,会根据max_length、num_objects_to_move和上一次垃圾收集到现在为止的最小链表长度,按一定的策略回收资源到中央堆中
同样可以在需要时减少某一个线程的max_length来转移内存,但是要等到那个线程下一次执行free,触发垃圾回收之后才会真正把内存返还中央堆
简而言之,就是:
小内存: 线程缓存队列 -> 中央堆 -> 中央页分配器(从系统分配)
大内存: 中央堆 -> 向系统请求
理论上性能提高的主要原因在线程缓存不加锁和少量操作的自旋锁上
不过按照它的实现方式,不适合多线程频繁分配大于8个分页(32KB)的内存。否则自旋锁争用会相当厉害,不过这种情况也比较少。而减少和中央堆交互又依赖于他的线程缓存长度自适应算法
还有就是它使用了外部的数据结构来管理span list,这样不会每次分配内存都要浪费header的长度。但是他的对齐操作又比ptmalloc多浪费了一些内存。(有点空间换时间的意思)
所以无论是ptmalloc还是tcmalloc都应该尽量减少大内存的分配和释放。尽量先分配、后释放
jemalloc
FreeBSD、NetBSD和Firefox的默认malloc
据作者说,高CPU核心数的情况下比tcmalloc性能还好
设计目标:
- 快速分配和回收
- 低内存碎片
- 支持堆性能分析
内存分配分为三部分
- 类似tcmalloc,以8、16、64字节等分隔开的small class
- 以分页为单位,等差间隔开的large class
- huge class
内存块管理也通过一种chunk进行,一个chunk的大小是2^k (默认4 MB)
通过这种分配实现常数时间地分配small和large对象,对数时间地查询huge对象的meta(使用红黑树)
默认64位系统的划分方式如下:
Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840] Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB] Huge: [4 MiB, 8 MiB, 12 MiB, …]
jemalloc也用了分配区(arena)来维护内存
线程按第一次分配small或者large内存请求的顺序Round-Robin地选择一个分配区 每个分配区都维护了一系列分页,来提供small和large的内存分配请求。并且从一个分配区分配出去的内存块,在释放的时候一定会回到该分配区
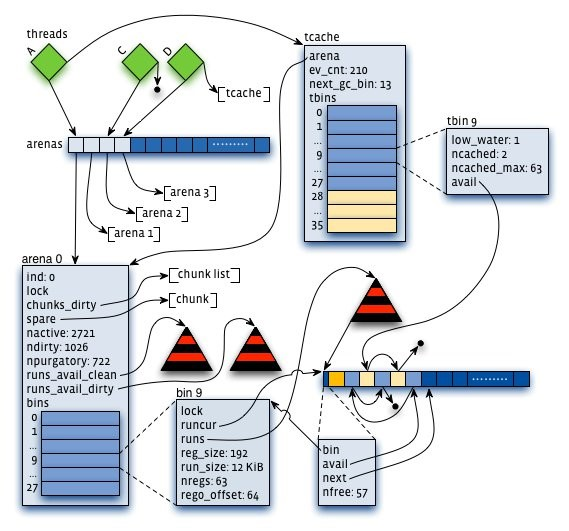
每个分配区内都会包含meta信息,记录了其对应的chunk列表,每个chunk的头部都记录了chunk的分配信息
使用某一个chunk的时候,会把它分割成很多个run,并记录到bin中
不同size的class对应着不同的bin,这点和前面两种分配器一样
bin里,都会有一个红黑树来维护空闲的run,并且在run里,使用了bitmap来记录了分配状态
和前面两种分配器不同的是,分配区会同时维护两组run的红黑树,一组是未被分配过内存(clean区域),另一组是回收的内存(dirty区域)。而且不是前面那两种分配器所使用的链表
同样,每次分配,都是选取最小且符合条件的内存块
但是优先从dirty区域查找
分配区设计和ptmalloc差不多。访问分配区的时候需要对其加锁,或者对某一个size的bin加粒度更小的锁。为减少锁征用,这里又参照tcmalloc引入了线程缓存。并且其线程缓存的垃圾回收机制和tcmalloc一样,也是基于分配请求的频率自动调整的 线程缓存的结构就像一个简化版的arena,加了一些垃圾回收的控制信息
简而言之,就是: 小内存(small class): 线程缓存bin -> 分配区bin(bin加锁) -> 问系统要 中型内存(large class):分配区bin(bin加锁) -> 问系统要 大内存(huge class): 直接mmap组织成N个chunk+全局huge红黑树维护(带缓存)
总结
jemalloc设计上比前两个复杂地多,内部用红黑树管理分页和内存块。并且对内存分配粒度分类地更细
一方面比ptmalloc的锁争用要少,另一方面很多索引和查找都能回归到指数级别,方便了很多复杂功能的实现
大内存分配上,内存碎片也会比tcmalloc少。但是也正是因为他的结构比较复杂,记录了很多meta,所以在分配很多小内存的时候记录meta数据的空间会略微多于tcmalloc
但是又不像ptmalloc那样每一个内存块都有一个header,而采用全局的bitmap记录状态,所以大量小内存的时候,会比ptmalloc消耗的额外内存小
大总结
这些内存管理机制都是针对小内存分配和管理。对大块内存还是直接用了系统调用
所以在程序中应该尽量避免大内存的malloc/new、free/delete操作
分配器的最小粒度都是以8字节为单位的,所以频繁分配小内存,int,bool什么的,仍然会浪费空间
无论是对bool、int、short进行new的时候,实际消耗的内存在ptmalloc和tcmalloc下64位系统地址间距都是32个字节
大量new测试的时候,ptmalloc平均每次new消耗32字节,tcmalloc消耗8字节
所以大量使用这些数据的时候不妨用数组自己维护一个内存池,可以减少很多的内存浪费。(STL的map和set一个节点要消耗近80个字节有这么多浪费在这里了)
多线程下对于比较大的数据结构,为了减少分配时的锁争用,最好是自己维护内存池
单线程的话无所谓了,不过自己维护内存池是增加代码复杂度,减少内存管理复杂度 255个分页以下(1MB)的内存话,tcmalloc的分配和管理机制已经相当nice,没太大必要自己另写一个
Windows下不同类型(int、short和bool)连续new的地址似乎是隔开的,可能是内部实现的粒度更小,不同size的class更多
10M次new的时候,debug模式下明显卡顿了一下,平均每次new的内存消耗是52字节(32位)和72字节(64位)[header更复杂?]
Release模式下很快,并且平均每次new的内存消耗是20字节(32位)和24字节(64位)
可以猜测VC的malloc的debug模式还含有挺大的debug信息。是不是可以得出他的header里,Release版本只有1个指针,Debug里有5个指针呢