一般单个虚拟地址空间就比物理内存要大,另每个进程都有自身的虚拟地址空间
内核和 CPU 必须考虑如何将实际可用的物理内存映射到虚拟地址空间的区域。一般用页表来为物理地址分配虚拟地址
虚拟地址关系到进程的用户空间和内核空间,而物理地址用来寻址实际可用的内存
物理内存页经常被称为页帧,而页一般用来指虚拟地址空间的页
内存分配管理方式
-
连续(块式)
为用户程序分配一个
连续的内存空间 -
非连续(页式 和 段式)
允个程序使用的内存分布在离散或者说
不相邻的内存中
-
块式管理 :
远古时代将内存分为几个固定大小的块,
每个块中只包含一个进程如果程序运行只需要很小的空间的话,分配的这块内存很大一部分几乎被浪费了。这些在每个块中未被利用的空间,称为碎片
-
页式管理 :
相比块式管理的划分力度更大,提高内存利用率,减少碎片
通过
页表对应逻辑地址和物理地址 -
段式管理 :
页式管理虽然提高了内存利用率,但是页式管理其中的页实际并无任何实际意义
段式管理把主存分为一段段的,每一段的空间又要比一页的空间小很多
最重要的是段是有实际意义的,如,主程序段 MAIN、子程序段 X、数据段 DATA 及栈段 STACK 等
段页式管理机制
结合段式管理和页式管理的优点。把主存先分成若干段,每个段又分成若干页,也就是说 段与段之间以及段的内部的都是离散的
分页和分段机制共同点和区别
- 共同点 :
- 都为提高内存利用率,减少内存碎片
- 都离散存储,分配方式。但每个页和段中内存是连续的
- 区别:
- 页大小固定,OS决定;段大小不固定,取决于程序
- 分页仅为满足os内存管理需求,而段是逻辑信息的单位,程序中体现为代码段,数据段,能够更好满足用户的需要
页表
将虚拟地址空间映射到物理地址空间的数据结构
实现两个地址空间的关联最容易的方法是使用数组,虚拟地址空间中每一页都分配一个数组项
IA-32 一个页 4KB ,虚拟地址空间 4GB 要100 万项的数组,才能完成这个映射关系。64 位体系结构情况更糟糕,每个进程都需要自身的页表,这个方法是不切实际的
因为虚拟地址空间的大部分区域都没有使用,因而也没有关联到页帧,就可以使用功能相同但内存用量少得多的模型: 多级分页
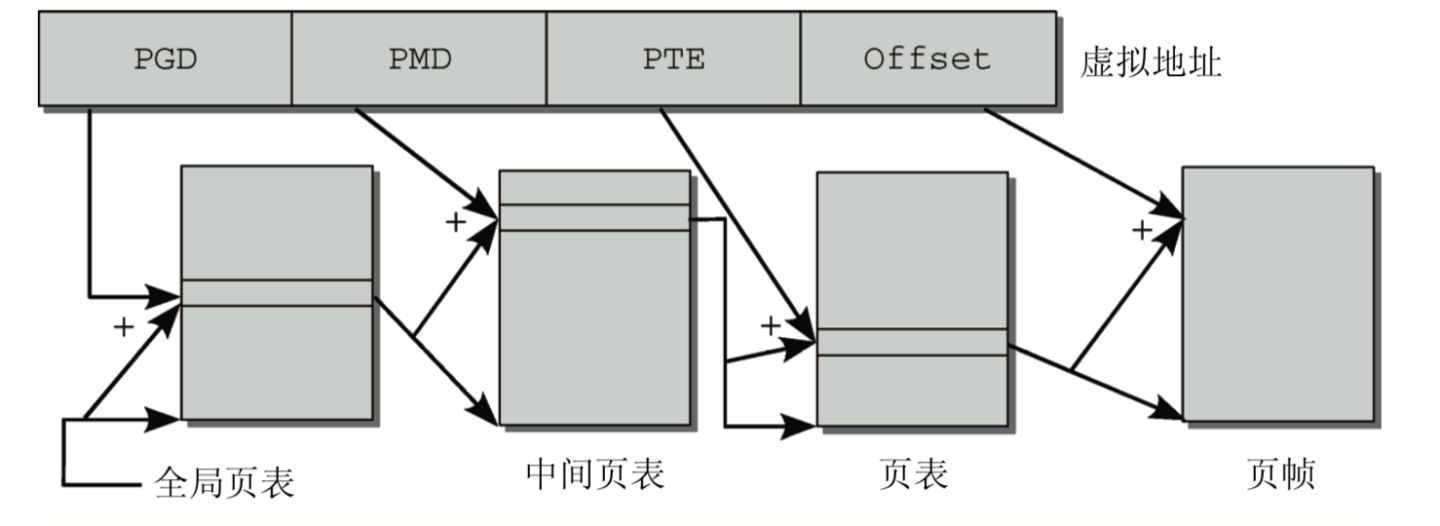
虚拟地址空间分多个部分
全局页目录项(PGD),一个进程有且只有一项,存储了中间页目录(PMD)的头指针,通过虚拟地址空间第二项作为偏移就可以得出该虚拟地址对应的 PMD 项,该项中存储了对应页表(PTE,Page Table Entry)的头指针,然后把虚拟地址中的第三项作为页表偏移,就可以得到对应页帧的物理地址,最后根据虚拟地址的最后一块 Offset 就能在页帧中进行寻址,指向页帧中的任意一个字节
通过这种多级分页的方式,就可以对那些不需要的虚拟地址区域,不创建中间页目录和页表,从而省下大量内存
缺点,每次访存都需要逐级访问多个数组才能将虚拟地址转换为物理地址,通过 TLB加速
CPU如何访问内存?
主板南北桥主要职责
-
北桥
CPU内存显卡等之间的数据传输
-
南桥
IO相关的、外部存储设备、BIOS相关的数据
内存管理,是程序的逻辑地址,通过分段机制转为线性地址,通过分页机制转为物理地址(CPU MMU模块支持),物理地址再通过北桥访问到具体的RAM设备,或者是ISA设备,或者PCI等IO相关(再通过南桥)
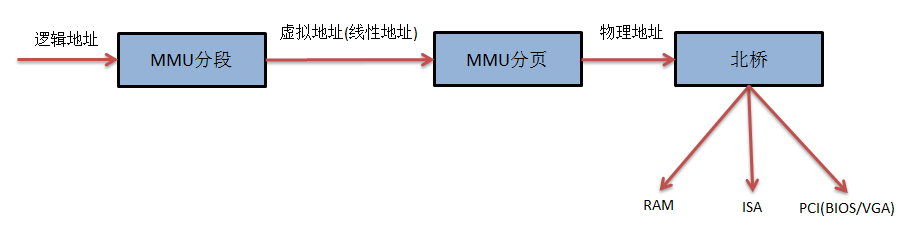
内存寻址的工作由Linux内核和MMU共同完成,Linux内核负责cr3,gdtr等寄存器设置,页表维护,页面管理,MMU则进行具体的映射工作
汇编最原始的访问物理地址通过CS:IP的分段机制来访问,x86架构历史原因是是分段机制,但Linux内存管理是分页机制
为向前兼容把整个内存段落拓宽为只有一段,段基址为0,段限长4G,只是在段类型和段访问权限上有所区分
Linux内核和所有进程共享1个GDT,不使用LDT(即系统中所有的段描述符都保存在同一个GDT中),这是为了应付CPU的分段机制所能做的最少工作
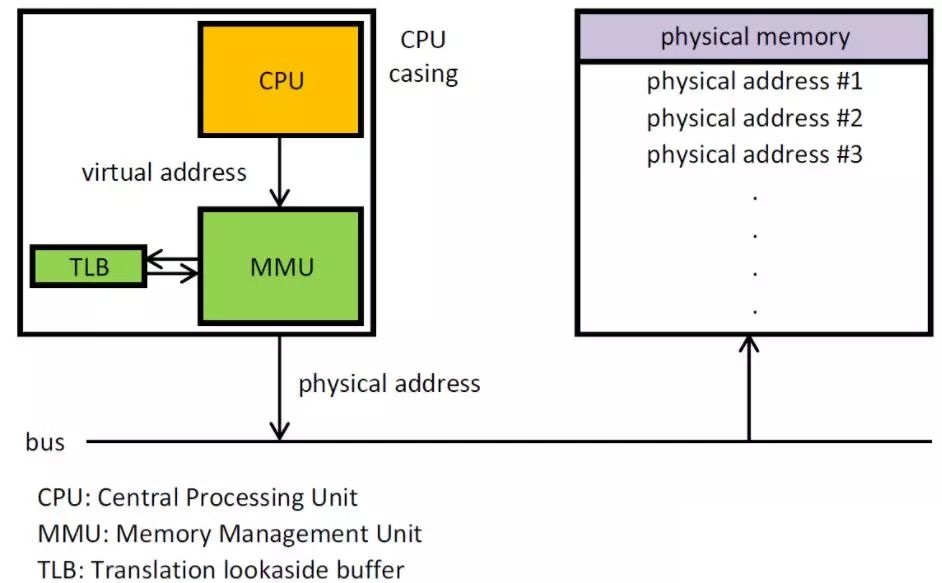
CPU 访问内存的时通过 MMU 把虚拟地址转化为物理地址,然后通过总线访问内存(QPI等)
MMU 通过页表把虚拟地址转换成物理地址,每一个进程都有一个自己的页表
页表包含每页所在物理内存的基地址,这些基地址与页偏移的组合形成物理地址,就可送交物理单元
物理内存的分配
内核分配内存时,必须记录页帧的已分配或空闲状态,以免两个进程使用同样的内存区域
内核可以只分配完整的页帧,将内存划分为更小的部分的工作,则委托给用户空间中的标准库。标准库将来源于内核的页帧拆分为小的区域,并为进程分配内存
内核中很多时候要求分配连续页。为快速检测内存中的连续区域,内核采用历经检验的技术: 伙伴系统
物理地址和虚拟地址的分布
物理地址空间布局
系统初始化时,据实际的物理内存的大小,为每个物理页面创建一个page对象,所有page对象构成一个mem_map数组

针对不同的用途,内核将所有的物理页面划分到 3 类内存管理区
-
ZONE_DMA
专门供 I/O 设备的 DMA 使用
DMA 使用物理地址访问内存,
不经 MMU,并且需要连续的缓冲区 -
ZONE_NORMAL
内核直接使用
内核空间的常用的数据如kernel代码、GDT、IDT、PGD、mem_map数组等,内核该虚拟地址与物理地址是
直接映射,不通过页机制 -
ZONE_HIGHMEM
内核不能直接使用
kernel 访问这些数据时才建立映射关系。比如,当内核要访问 I/O 设备存储空间时,就使用 ioremap() 将位于物理地址高端的 mmio 区内存映射到内核空间的 vmalloc area 中,在使用完之后便断开映射关系
-
MMIO
IO设备和内存共享同一个地址总线,地址空间相同
而在PMIO中,IO设备和内存的地址空间是隔离的
简单说就是MMIO将IO地址编入内存地址中,调用相应的内存地址即调用到相应的IO设备,而至于往下的是像Inter的int/out指令端口独立编址还是ARM的统一编址则不管
-
Linux物理地址和虚拟地址的关系
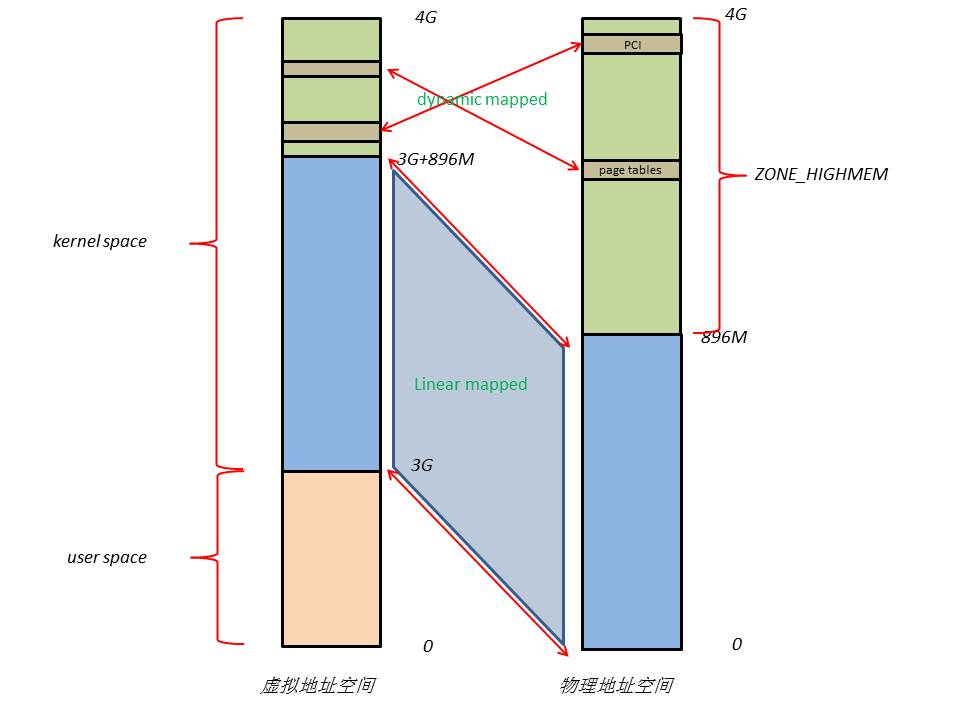
4G 线性地址空间分为2部分,03G 为 user space,3G4G 为 kernel space
由于分页机制,内核访问物理地址空间,要经映射关系,通过虚拟地址来访问
为能访问所有物理地址空间,将全部物理地址空间 4G 直接映射到 1G 的内核线性空间中,不可能
0~896M 物理地址空间直接映射到kernel线性地址空间,它便可以随时访问 ZONE_DMA 和 ZONE_NORMAL 里的物理页面
内核剩下的 128M 线性地址空间不足以完全映射所有的 ZONE_HIGHMEM,Linux 采取动态映射方法
按需将 ZONE_HIGHMEM 里的物理页面映射到 kernel space 的最后 128M 线性地址空间里,使用完之后释放映射关系,以供其它物理页面映射
虽然这样存在效率的问题,但是内核毕竟可以正常的访问所有的物理地址空间了
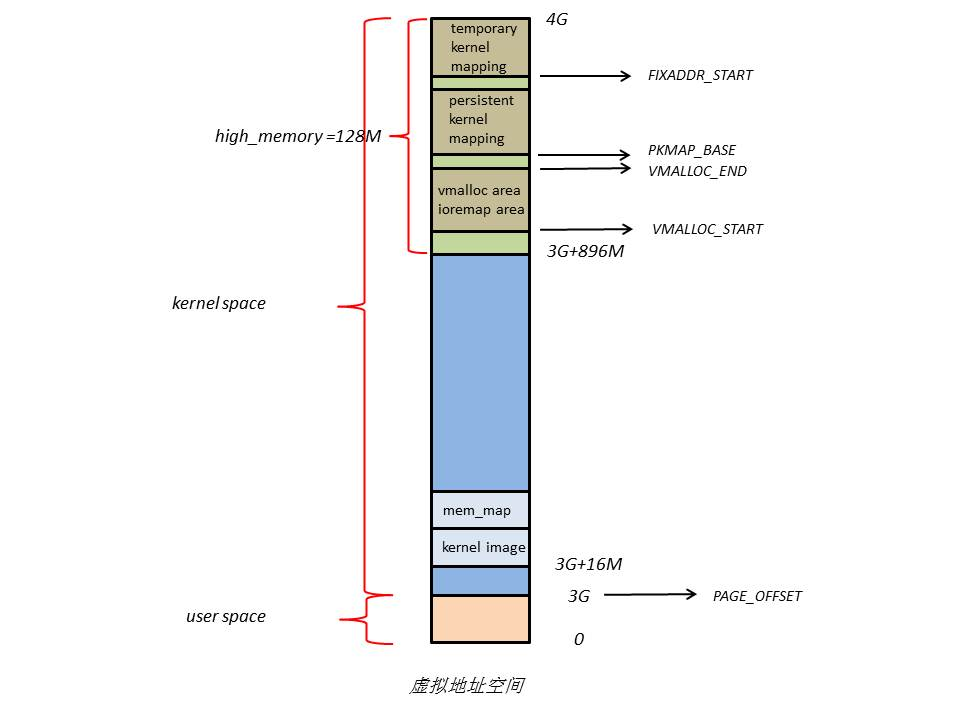
16M 内核空间用于 DMA
内核空间高端的 128M 地址主要由3部分组成
-
vmalloc area
提供连续的虚拟地址,但是指向的物理地址不一定连续
-
持久化内核映射区
方便通过物理地址找到对应的虚拟地址,用于固定的线性地址常量,例如0xffffc000,且该常量在编译阶段就可以确定
创建持久内核映射的函数kmap()可能会阻塞当前进程,因此不能用在中断上下文中
-
临时内核映射区
与持久内核映射相比更快,而且不会阻塞当前进程,因此可以用在中断上下文中
弱点,使用它的代码不能睡眠。因为每一个CPU都有独自的13个临时映射地址如果切换进程可能导致该地址被改变
