一些概念
数据在内存中以 page 为单位存在; 在cache 里以 cache line 为单位
对称多处理器(SMP)系统中,每个处理器都有各自的本地 cache(local cache)。内存系统必须保证 cache 一致性(cache coherence)
cache line 是 cache 与主存进行交换的单位,是能被 cache 处理的内存 chunks,chunk 的大小即为 cache line size(典型大小 32,64 及 128 Bytes)
伪共享:缓存系统以 cache line为单位存储,多线程修改互相独立的变量时,如果这些变量共享同一个cache line,就会无意中影响彼此的性能
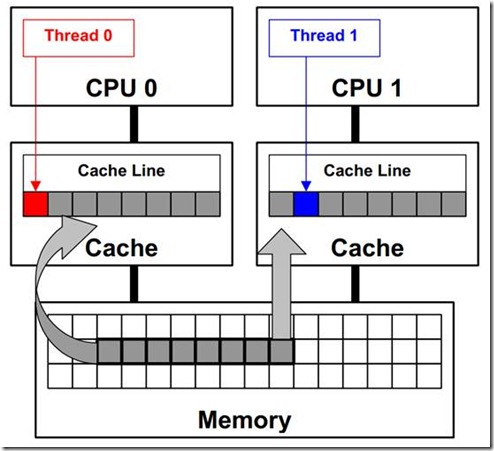
不同处理器上的线程修改了位于同一个 cache line 上的数据,导致 cache line 失效,强制内存更新来维护 cache 一致性
问题在于这一切都在幕后悄然发生,没有任何编译告警提示你说这段代码并发性能会非常低下
java long 8 字节,一个 cache line 可放 long[8] 数组
访问 long[0] ,0-7 元素都被会加载到 cache 里,即便此后并不需要访问 1-7 的元素
好处:
恰好访问完 0 元素就像访问 1 的话(遍历数组),赚到
副作用:
整体加载,同一 cache line 上的数据是绑在一根绳上的蚂蚱
如果数据结构中的项在内存中不是彼此相邻的(如链表),将得不到免费缓存加载所带来的优势,并且在这些数据结构中的每一个项都可能会出现缓存未命中
为了保证多 cache 下数据一致性,多处理器架构服从 MESI协议
一些避免伪共享手段
-
编译器用线程私有临时数据消除伪共享
-
手动字节填充
JDK 8 前一般通过代码手动字节填充避免多个变量存放在同一个缓存行中
public class FalseShareTest implements Runnable {
public static int NUM_THREADS = 4;
public final static long ITERATIONS = 500L * 100L * 100L;
private final int arrayIndex;
private static VolatileLong[] longs;
public static long SUM_TIME = 0L;
public FalseShareTest(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
for (int j = 0; j < 10; j++) {
System.out.println(j);
if (args.length == 1) {
NUM_THREADS = Integer.parseInt(args[0]);
}
longs = new VolatileLong[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
final long start = System.nanoTime();
runTest();
final long end = System.nanoTime();
SUM_TIME += end - start;
}
System.out.println("平均耗时:" + SUM_TIME / 10);
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseShareTest(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
@Override
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong {
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; //屏蔽此行
}
}-
sun.misc.Contended
-
编译指示
__declspec (align(64)) int thread1_global_variable;
__declspec (align(64)) int thread2_global_variable;more
MOESI
比如 AMD Coherent HyperTransport (HT)
AMD ccHT ,所有 transaction 都是先发送到相应 memory block(cache line) 的 home node,然后由这个 home node 发出广播 message,从而做到了对同一个 memory block (cache line) 操作的 serilization
对于某个处于 modified 状态的 cache line A,如果有其他的 node 发生了对它的数据的 read miss,A 可以把数据发送给发生 read miss 的 node(假设写到 cache line B 上)
B 的状态被设为 shared,这个 A 的状态则被修改为 owner
如果 A 自己发生了 write hit,会通过 home node 来 broadcast invalidate 的 message,这是 owner 状态和 modified 状态不同的地方:如果是 modified 状态,自己的 write hit 不产生任何 message。 传统 MESI,对于处于 modified 状态的 cache line,如果被其他 processor 读取,必须把它写回 memory,并把自己改到 shared 状态