1.1 不同功能物理分离实现伸缩
纵向分离
业务流程不同部分分离部署,实现伸缩

横向分离
不同业务模块分离部署,实现伸缩

1.2 单一功通过集群规模实现伸缩
应用服务器集群性和数据服务器集群伸缩,对数据状态管理的不同,技术实现有很大区别
一头牛拉不动车的时候,不要去寻找一头更强壮的牛,而是用两头牛来拉车
应用服务器集群伸缩设计
应用服务器应该被设计成无状态的
负载均衡
HTTP 重定向
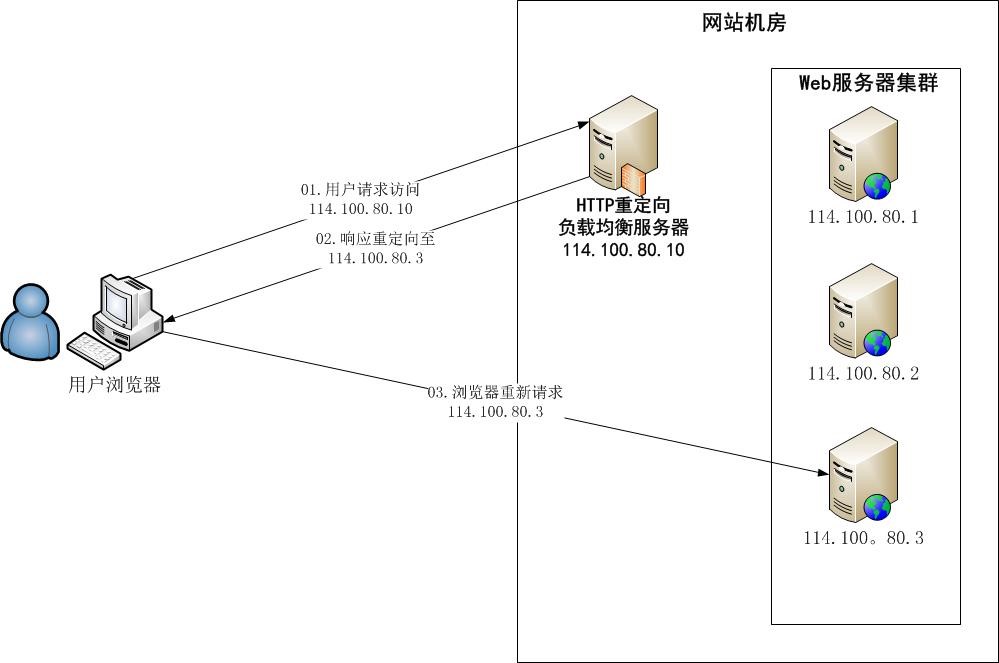
优点:简单易行
缺点:
浏览器要两次请求才完成一次访问
重定向服务器自身可能成为瓶颈,整个集群伸缩性规模有限
302 重定向可能被搜索引擎判断为 SEO 作弊,降低搜索排名
DNS
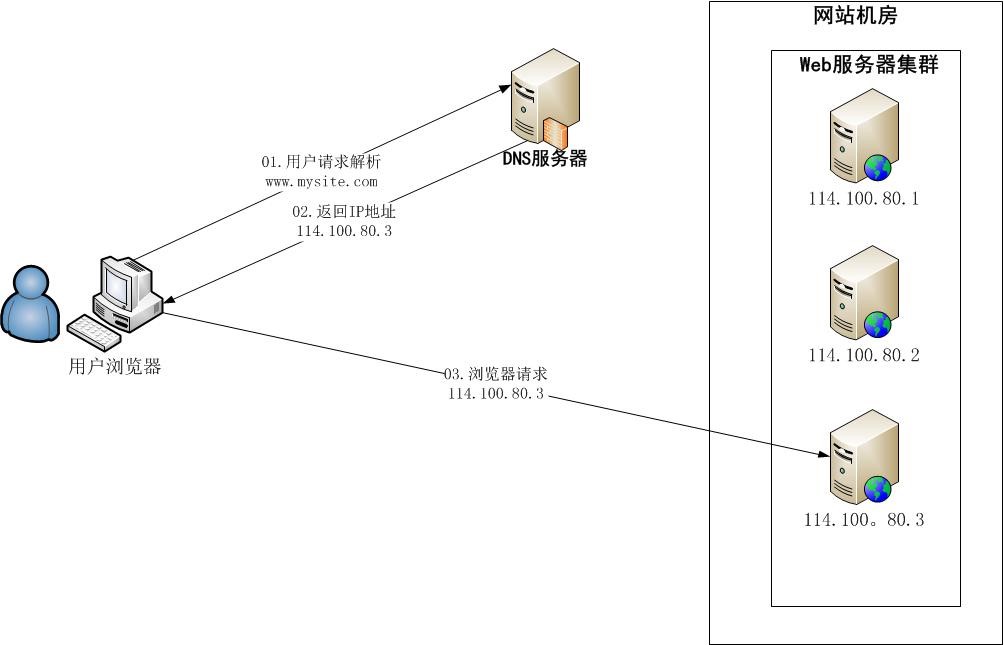
优点:负载均衡转交给 DNS,省掉管理维护负载均衡服务器
缺点:
DNS 是多级解析,每一级 DNS 都可能缓存 A 记录,某台服务器下线后,修改 DNS 的 A 记录,较长时间才生效。用户访问已经下线的服务器造成访问失败
DNS 控制权在域名服务商,无法更多改善和管理
大型网站部用DNS作第一级负载均衡手段,解析到同样提供负载均衡的内部服务器,这组内部服务器再进行负载均衡,请求分发到真实的 Web 服务器上
云主机的话,同样是DNS解析到云主机的load balance
反向代理
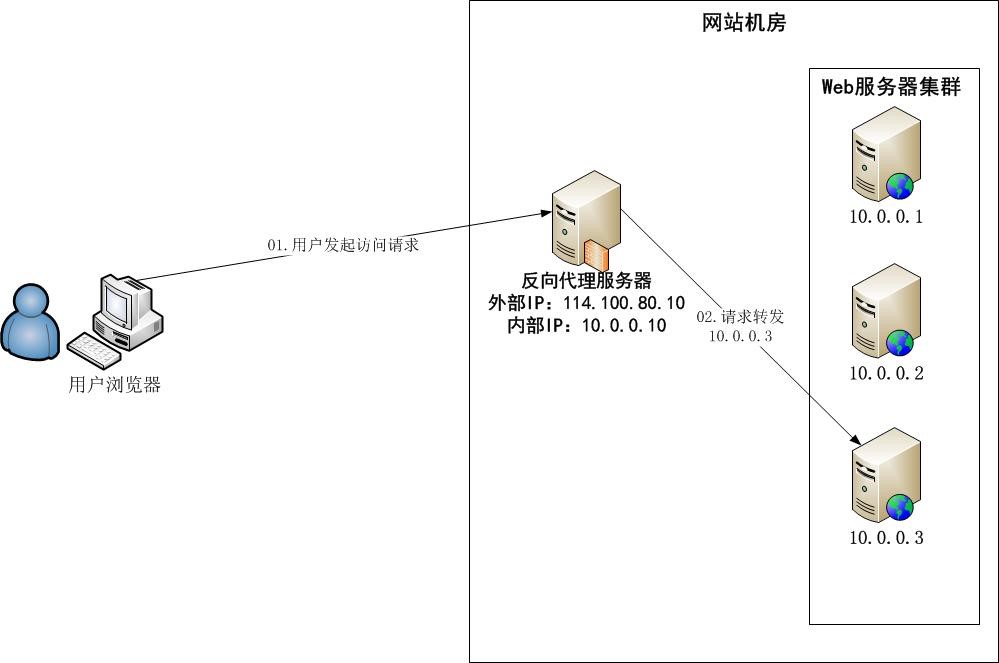
IP 负载均衡
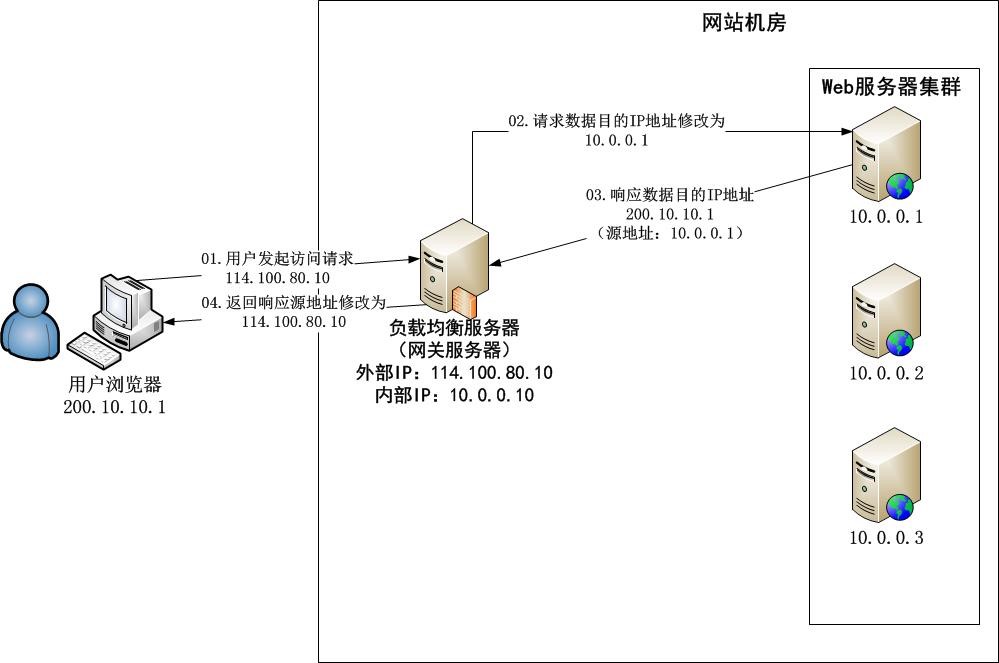
优点:内核完成数据分发,较反向代理负载均衡(应用层分发数据)有更好性能
缺点:集群最大响应数据吞吐量受制于负载均衡服务器网卡带宽
数据链路层负载均衡
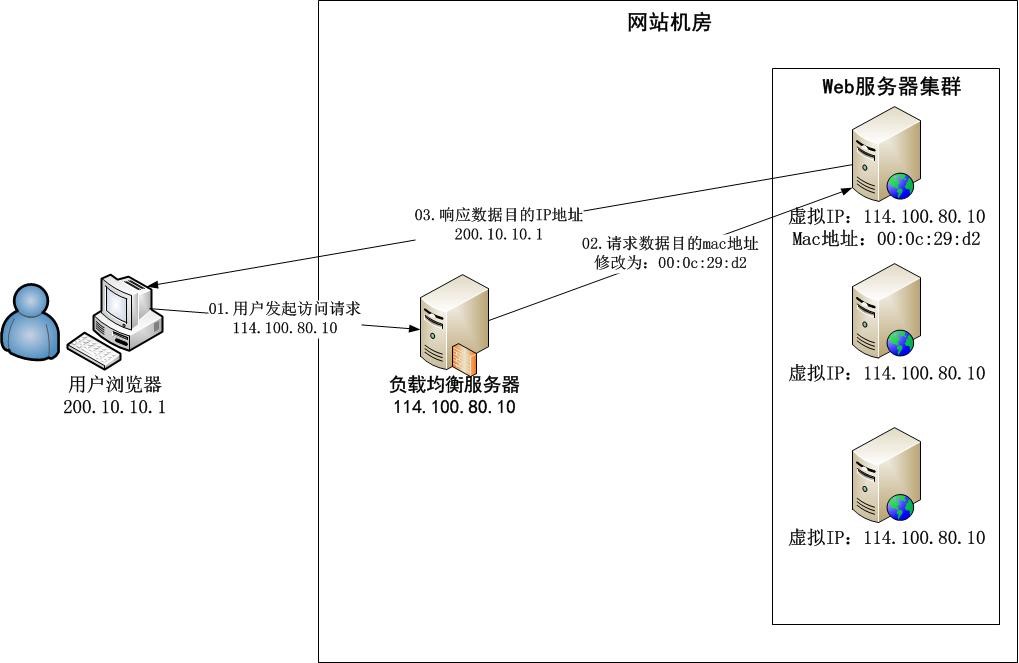
又称作三角传输模式,分发过程中不修改 IP 地址,只修改 mac 地址, IP 地址一致,不需要通过负载均衡器地址转换,响应包直接返回用户浏览器,避免负载均衡器网卡带宽成为瓶颈。直接路由方式(DR)
分布式缓存集群伸缩性设计
不能使用简单的负载均衡手段来实现,缓存访问请求不可以在缓存服务器集群中的任意一台处理,必须先找到缓存有需要的数据的服务器,然后才能访问
伸缩性设计的目标:让新上线的缓存服务器对整个分布式缓存集群影响最小,也就是说新加入缓存服务器后应使整个缓存服务器集群中已经缓存的数据尽可能还被访问到
简单的路由算法(服务器数取余 Hash)无法满足业务发展时服务器扩容的需要:缓存命中率下降
例:3 台扩至 4 台时,普通余数 Hash 算法导致大约 75%(3/4)被缓存了的数据无法正确命中,集群规模增大,比例线性上升
100 台集群加入一台,不能命中概率99%(N/N+1)
一致性 Hash ,3 台扩到 4 台,继续命中概率为 75%,远高于普通余数 Hash 的 25%,集群规模越大,继续命中概率也增大
100 台增加 1 台,概率 99%