为什么要有 ziplist
- 普通双向链表,两个指针,存储数据很小情况下,实际数据大小可能还没有指针占用的内存大
- 链表在内存一般不连续,遍历相对比较慢
ziplist 内存紧凑型列表,节省内存空间、提升内存使用率
结构
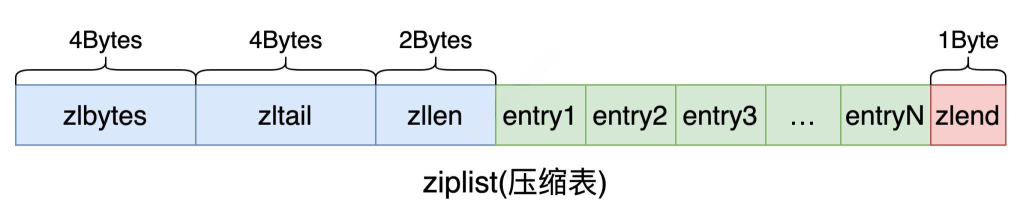
ziplist
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
entry
<prevlen> <encoding> <entry-data>
ziplist 是一个特殊的双向链表,特殊之处在于:没有维护双向指针,prev、next,而是存储了上一个 entry 的长度和当前 entry 的长度,通过长度推算下一个元素
- 本质上就是一个字节数组
- 为节约内存而设计的一种线性结构
- 可以包含多个元素,每个元素可以是一个字节数组或一个整数
通过宏定义操作字段
为什么不能一直是 ziplist
ziplist 紧凑存储,没有冗余空间,新插入元素,就需要扩展内存,两种情况:
- 分配新的内存,将原数据拷贝到新内存
- 扩展原有内存
元素个数
ziplist 用uint16_t 2 字节来记录元素个数,如果=UINT16_MAX(65535),节点的真实数量需要遍历整个压缩列表才能计算得出
存在问题
- 查询效率 O(n)
- 内存重分配
- 连锁更新
cascade update
压缩列表构造的一个弊端
源于 previous_entry_length 属性的设定,这个属性可能占 1 字节,也可能占 5 字节,实际占用空间大小和前一个节点大小有关。如果在某个位置新插入一个较大的节点,或者删除一个大节点后的节点,可能就会导致后面节点的 previous_entry_length 属性由 1 字节变成 5 字节,而因为该属性的改变也会导致该 entry 大小的改变,从而可能引发该 entry 大于等于 254 字节,进而导致后面的 entry 大小继续改变。这个改变可能会波及到整个压缩列表,所以称之为级联更新
级联更新在最坏情况下需要对压缩列表执行 N 次空间重分配操作,每次重分配的复杂度是 ON,级联更新最坏复杂度为 ON 方
虽然级联更新存在,但是出现概率很低,几乎可以忽略不计
历史 nextdiff == -4 && reqlen < 4 bug