业务洗数据,binlog变更发至rabbitmq, 堵死现象分析
事件
业务 sql 洗大表数据,产生大量binlog,发往rabbitmq
rabbitmq node节点CPU跑满
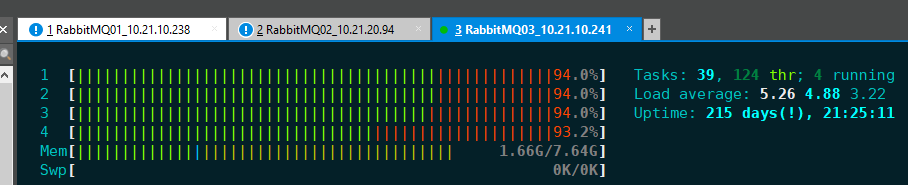
整个rabbitmq集群不可用

node 2、3是ram 节点(事后运维说观察到上图CPU爆满,才将disk节点改成ram,正是由此,整个rabbitmq集群不可用)

由于node 2 3变成ram节点,大量堵着未消费完的数据,还未同步结束,node 2内存占满

本次解决方案:暴力重启整个rabbitmq集群
发现堆积的数据直接消失

相关解决方案
业务经常会面临此问题,消息生产太快,消费不过来,导致队列堆积很长,把服务器内存耗尽,这时RabbitMQ的处理能力很低下
社区总结起来解决方案大体包括:
- 增加消费者的处理能力,或减少发布频率
- 单纯升级硬件不是办法,只能起到一时的作用
- 考虑使用队列最大长度限制,RabbitMQ 3.1支持
- 给消息设置年龄,超时就丢弃
rabbitmq 原理
-
rabbitmq没有消费者的情况下,生产者持续向mq发消息,发送速率不受影响
-
但当有新的消费者连接上mq并开始接收消息时,生产速率大幅降低
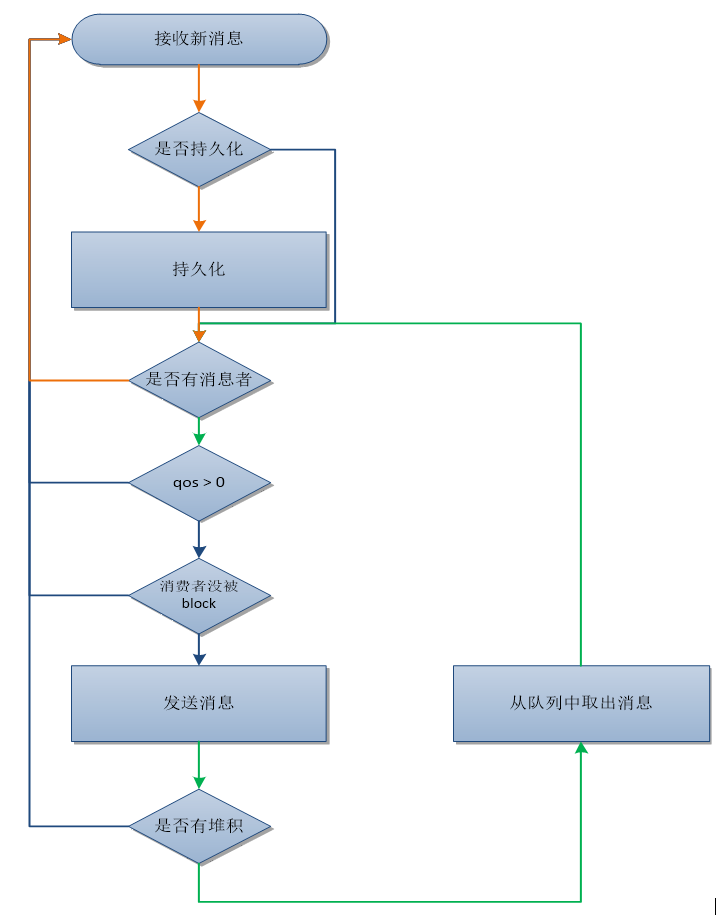
Rabbitmq的中处理队列收发逻辑的是一个有穷状态机进程,它对消息的处理流程可以概括为
-
既有生产者也有消费者时,状态机处理流程 :接收消息->持久化->发送消息->接收消息 –> … ->
在
流控机制的控制下,收发速率能够保持基本一致,队列中堆积的消息数会非常低 -
没有消费者时,处理流程如橙色线条,MQ会持续接收消息并持久化直到磁盘被写满,因为没有发送逻辑,这时可以达到
更高的生产速率 -
有消息堆积时,处理流程如绿色线条,MQ会持续从队列中取出堆积的消息将其发送出去,直到
- 没有了堆积消息
- 或消费者的qos被用光
- 或没有消费者
- 或消费者的channel被阻塞
如果一直没有满足上述4个条件之一,MQ就会持续的发送堆积消息,不去处理新来的消息,在流控机制的作用下,发送端就被阻塞了
总结
从上述描述可以看出,消息堆积后,发送速率降低是MQ的处理流程使然,不是bug
这样的流程设计基于以下两个原因:
-
让堆积的消息更快的被消费掉,降低消息的时延
-
MQ中堆积的消息越少,每个消息处理的平均开销就越少,可以提高整体性能,所以需要尽快将堆积消息发送出去
应对措施
- 打破发送循环条件
- 设置合适的qos值,当qos值被用光,而新的ack未被mq接收时,就可以跳出发送循环,去接收新的消息
- 消费者主动block接收进程,消费者感知到接收消息的速度过快时,主动block,利用block与unblock方法调节接收速率。当接收进程被block时,mq跳出发送循环
-
建立新的队列 若服务器cpu资源有较多剩余,而又不需要保证消息的顺序的情况下可以通过建立新的vhost,在该vhost下创建queue,生产者将消息发送掉新的queue,消费者同时订阅新旧queue
-
使用缓存
在生产者端使用缓存,当生产速率受到流控限制时,缓存数据。在堆积的消息被处理完后,生产速率恢复正常时,此时将缓存的数据发送给MQ
-
更新rabbitmq版本
2.8.4中,在有大量消息堆积时,生产速率会受到抑制,但生产者不会完全被阻塞
-
加机器
性能调优
避免雷区
避免流控机制触发
- 服务端默认配置是当内存使用达到
40%,磁盘空闲空间小于50M,启动内存报警,磁盘报警;报警后服务端触发流控(flowcontrol)机制 - 一般发布端发送消息速度快于订阅端消费消息的速度时,队列中堆积了大量的消息,导致报警,就会触发流控机制
- 触发流控机制后,RabbitMQ服务端接收发布来的消息会变慢,使得进入队列的消息减少
- 与此同时RabbitMQ服务端的消息推送也会受到极大的影响,服务端推送消息的频率会大幅下降,等待下一次推送的时间,有时等1分钟,有时5分钟,甚至30分钟
- 因此要做好数据设计,使发送速率和接收速率保持平衡,而不至于引起服务器堆积大量消息,进而引发流控。通过增加服务器集群节点,增加消费者,来避免流控发生,治标不治本,而且成本高
- 服务器单节点,单网卡全双工情况下,测试发现发布速度过快,压满发布PC机带宽,对于服务器来说,下行(接收)带宽也会压满,可是上行(转发递送)带宽却出现了明显的下降,似乎有一个争抢。可能是导致触发流控的原因
消息大小不要超过4MB
- 用线程来模拟50个发布者和50个订阅者
消息包大小由1K到10MB,当包大小达到4.5MB时,服务器的性能出现明显的异常,传输率尤其是每秒订阅消息的数量,出现波动,不稳定;同时有一部分订阅者的TCP连接出现断开的现象。可能是客户端底层或者RabbitMQ服务端在进行拆包,组包的时候,出现了明显的压力,而导致异常的发生
磁盘也可能形成瓶颈
磁盘也可能形成瓶颈,如果单台机器队列很多,确认只在必要时才使用duration(持久化),避免把磁盘跑满;
队列的消息大量累积后
队列的消息大量累积后,发送和消费速度都会受到影响,导致服务进一步恶化,可采用的方法是,额外的脚本监控每个队列的消息数,超过限额会执行purge操作,简单粗暴但是有效的保证了服务稳定
单机限制
由于用线程模拟大量发布者,且是服务器单节点,受客户端主机网卡的限制,发布线程没有速度控制,导致有大量数据发送,服务器带宽下行速率也满负荷,上行带宽却明显低于下行速率,导致服务器内存有大量消息堆积,进而触发RabbitMQ服务器paging操作,才出现了上述不稳定和订阅者断开现象
对发布端做适当流量控制,断开连接现象不再出现,但每秒消息数仍然不稳定
模式对性能的影响
分析三种模式 direct fanout topic
不同的模式对于新建交换机、新建队列、绑定等操作性能影响不大,
但是在direct模式下明显消息发布的性能比其他模式强很多,并且消息发送到相同队列比发送到不同队列性能稍好
持久化对消息性能的影响参考
在消息持久化模式下:
发布:13888msg/s
订阅:15384msg/s在消息非持久化模式下:
发布:18867msg/s
订阅:26315msg/s问题分析/解决方案
问题分析:
RabbitMQ内存占用已经 7.8G 允许的值为 6G左右
vm_memory_high_watermark 是0.4 也就是物理内存的40% ;服务器为16G * 40% = 6.4G
一般在产生的原因是长期的生产者发送速率大于消费者消费速率导致. 触发了RabbitMQ 的流控
解决方案:
- 增加消费者端的消费能力,或者增加消费者(根本解决)
- 控制消息产生者端的发送速率(不太现实)
- 增加mq的内存(治标不治本)
参数调优
-
vm_memory_high_watermark
配置内存阈值,建议小于0.5,因为Erlang GC在最坏情况下会消耗一倍的内存
-
vm_memory_high_watermark_paging_ratio
配置paging阈值,该值为1时,直接触发内存满阈值,block生产者
-
IO_THREAD_POOL_SIZE
CPU大于或等于16核时,将Erlang异步线程池数目设为100左右,提高文件IO性能
-
hipe_compile
开启Erlang HiPE编译选项(相当于Erlang的jit技术),能够提高性能20%-50%。Erlang R17后HiPE已经相当稳定,RabbitMQ官方也建议开启此选项
-
queue_index_embed_msgs_below
RabbitMQ 3.5版本引入了将小消息直接存入队列索引(queue_index)的优化,消息持久化直接在amqqueue进程中处理,不再通过msg_store进程。由于消息在5个内部队列中是有序的,所以不再需要额外的位置索引(msg_store_index)。该优化提高了系统性能10%左右
-
queue_index_max_journal_entries
journal文件是queue_index为避免过多磁盘寻址添加的一层缓冲(内存文件)。对于生产消费正常的情况,消息生产和消费的记录在journal文件中一致,则不用再保存;对于无消费者情况,该文件增加了一次多余的IO操作
Java
如何优化消费端处理缓慢造成的消息堆积问题?
默认情况下,rabbitmq消费者为单线程串行消费,这也是队列的特性
源码在org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer中
private volatile int prefetchCount = 1;
private volatile int concurrentConsumers = 1;可以通过设置并发消费提高消费的速率,从而减少消息堆积的问题
-
concurrentConsumers设置的是对每个listener在初始化的时候设置的并发消费者的个数
-
prefetchCount是每次一次性从broker里面取的待消费的消息的个数
org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer
启动的时候会根据设置的concurrentConsumers创建N个BlockingQueueConsumer(N个消费者)
protected int initializeConsumers() {
int count = 0;
synchronized (this.consumersMonitor) {
if (this.consumers == null) {
this.cancellationLock.reset();
this.consumers = new HashSet<BlockingQueueConsumer>(this.concurrentConsumers);
for (int i = 0; i < this.concurrentConsumers; i++) {
BlockingQueueConsumer consumer = createBlockingQueueConsumer();
this.consumers.add(consumer);
count++;
}
}
}
return count;
}prefetchCount是BlockingQueueConsumer内部维护的一个阻塞队列LinkedBlockingQueue的大小,其作用就是如果某个消费者队列阻塞,就无法接收新的消息,该消息会发送到其它未阻塞的消费者