RMQ用了好多年,该重新回顾一下了
RMQ阿里说法是不遵循任何规范,不能完全用JMS那一套东西来看它,经历了Metaq1.x、Metaq2.x的发展和淘宝双十一的洗礼,功能和性能上远超ActiveMQ
RMQ 原生支持分布式,ActiveMQ原生存在单点性
RMQ可保证严格消息顺序,ActiveMQ无法保证!
RMQ亿级消息堆积,依然保持写入低延迟!
PUSH和PULL,Push好理解,消费者端设置Listener回调;Pull控制权在于应用,应用需要主动的调用拉消息方法从Broker获取消息,应用需要做好消费位置记录,否则导致消息重复消费
Metaq1.x/2.x,分布式协调用zk,RMQ自己实现了NameServer,更轻量,性能更好!
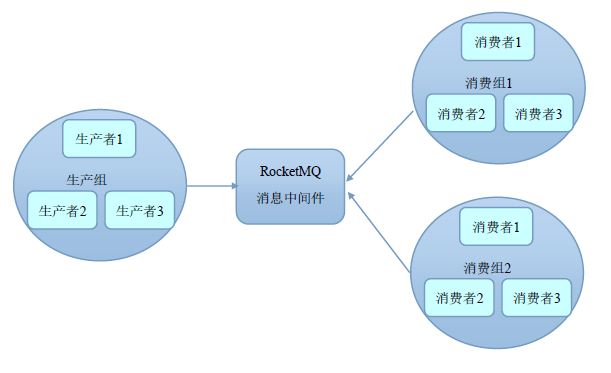
通过Group机制,RMQ天然的支持消息负载均衡!
某Topic 9条消息,其中一个Consumer Group有3个实例(3个进程 OR 3台机器),每个实例均摊3条消息!( RMQ 只有一种模式,发布订阅模式。)
AMQ ,生产消息的时会提供是否持久化的选择,但RMQ消息是一定会被持久化的!
PUSH consumer
consumer.setConsumeMessageBatchMaxSize(10),即使设置了批量的条数,最大是10,并不意味着每次batch的都是10,只有在消息有积压的情况下才有可能。且Push Consumer最佳实践方式就是一条条的消费,如果需要batch,可以使用Pull Consumer
务必保证先启动消费者进行Topic订阅,然后在启动生产者进行生产(否则极有可能导致消息的重复消费,重复消费,重复消费!重要的事情说三遍!
重试
如网络抖动导致生产者发送消息到MQ失败,1秒内没成功,重试3次
|
|
通过ConsumeGroup机制,实现了天然的消息负载均衡!
通过ConsumeGroup实现将消息分发到C1/C2/C3/……的机制,将非常方便的通过加机器来实现水平扩展!
如C2发生了重启,一条消息发往C3进行消费,但是这条消息的处理需要10S,而此时C2刚好完成重启,C2是否可能会收到这条消息呢?是的,也就是consume 的重启,或者水平扩容,或者不遵守先订阅后生产消息,都可能导致消息的重复消费!
至于消息分发到C1/C2/C3,其实也是可以设置策略的
前身 metaq
zk做服务发现和offset存储,pull机制,多种offset存储(db、file、zk、自定义) 等增强
MetaQ事务实现跟ActiveMQ类似,redo日志,JTA实现分布式事务
网络协议跟memcached文本协议类似(xmemcached作者),引入opaque的映射字段,提高请求并行度
文本协议,其他语言客户端相对容易,管理服务器容易,stats协议,telent就可以获取服务器运行状况
HornetQ用JNI基于异步IO做了更多优化
组件
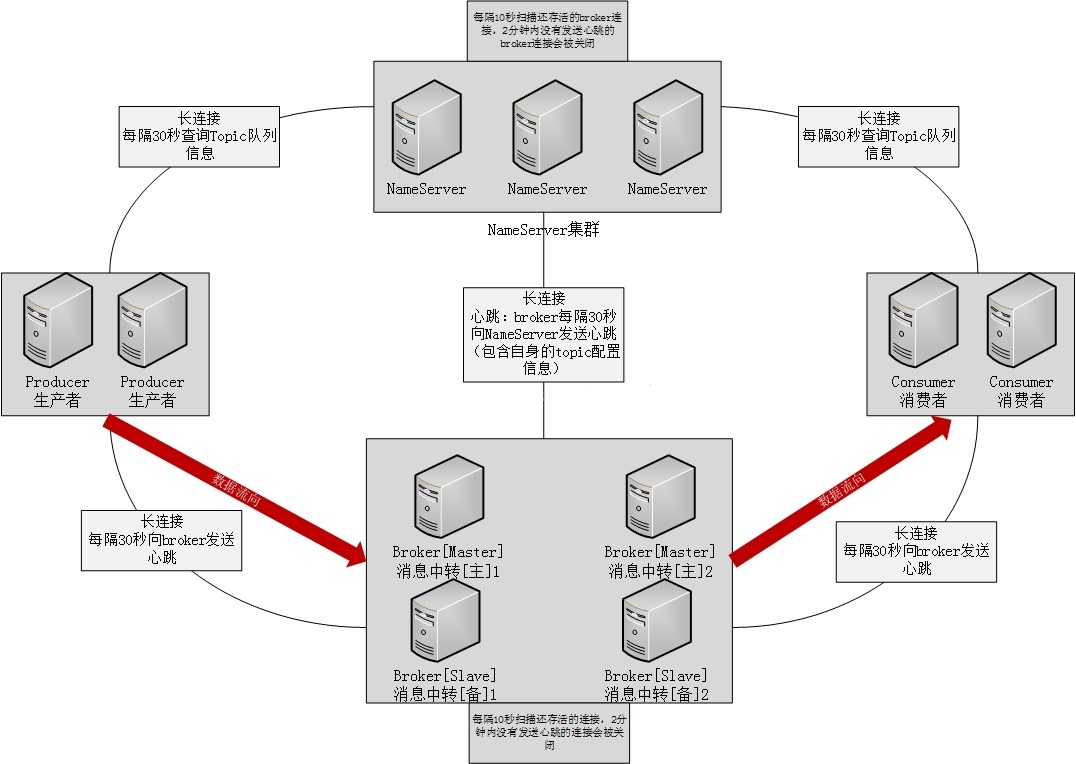
name server
2 主要作用
- 维护 Broker 地址,broker启动去NS注册
- 维护Topic和其队列地址列表,broker心跳带上Topic信息
稳定性
- 互相独立,彼此不通信,单台挂不影响其他NS,全部挂也不影响业务。无状态
- 不频繁读写,开销小
broker
和nameserver关系
连接
每broker和所有NS长连
心跳
间隔:硬编码30秒向所有NS发心跳,包含自身topic信息
超时:NS硬编码10秒扫描所有存活broker,2分钟没发心跳,断开
断开
时机:broker挂,心跳超时,NS主动关闭
动作:长连一断开,NS立即感知,更新topic与队列关系,但不通知生产和消费者
负载均衡
topic分布在多broker上,一个broker可配置多个topic,多对多
topic消息量大,应多配几个队列,分布在不同broker上,减轻单点压力
可用性
消息分布在各broker,某台宕机,该broker消息读写都受影响
salve定时从master同步数据,master宕机,slave提供读,不能写入消息,对应用透明(client sdk已封装)
两个关键点:
- broker master宕机,生产者和消费者多久能发现?
默认最多30秒,可由应用参数缩短时间。时段内,发broker的消息失败,且broker消息无法消费,消费者不知该broker已挂
- 消费者得到master宕机通知后,转向slave消费,但slave不能保证master消息100%都同步过来了,有少量消息丢失。最终不丢,master恢复,未同步过去的消息会被消费掉
可靠性
发broker的消息,有同步和异步刷盘机制
同步刷盘,消息写入物理文件才返回成功,非常可靠(进程退出后os确保进程遗留在内存的数据刷盘) 异步刷盘,机器宕机,才产生消息丢失
消息清理
- 扫描间隔
默认10秒,broker参数cleanResourceInterval
- 空间阈值
磁盘空间达到阈值,不接受消息,broker日志,消息发送失败,固定值85%
- 清理时机
默认凌晨4点,broker参数deleteWhen;或磁盘空间到阈值
- 文件保留时长
默认72小时,broker参数fileReservedTime
读写性能
- 文件内存映射方式操作文件,避免read/write系统调用和实时文件读写,性能非常高
- 永远一个文件在写,其他文件在读
- 顺序写,随机读
- linux sendfile机制,消息内容直接输出sokect管道,避免系统调用
系统特性
- 内存越大性能越高,避免swap
- IO密集
- cpu load高,使用率低,cpu占用后,大部分时间在IO WAIT
- 兼顾安全和性能,用RAID10阵列
- 要求高转速大容量磁盘
消费者
与nameserver关系
连接
和一台NS长连,定时查询topic配置,NS挂,自动连接下一个,直到有可用连接为止,自动重连
心跳
与NS没心跳
轮询时间
默认30秒从NS获取所有topic最新队列情况,broker宕机,最多30秒才能感知
DefaultMQPushConsumer的pollNameServerInteval参数
与broker关系
连接
和该消费者关联的所有broker长连
心跳
默认30秒向所有broker发心跳,DefaultMQPushConsumer的heartbeatBrokerInterval参数
broker硬编码10秒扫所有存活连接,当前时间-最后更新时间>2分钟没心跳,关闭连接,并向该消费者分组的所有消费者发通知,分组内消费者重新分配队列继续消费
断开
时机:消费者挂 或 心跳超时导致broker主动关闭
动作:长连断开,broker立即感知,并发通知,分组内消费者重新分配队列继续消费
负载均衡
集群消费,多台机器共同消费一个topic的多个队列,一个队列只会被一个消费者消费。某消费者挂掉,分组其它消费者会接替挂掉的继续消费
消费机制
本地队列
消费者不断从broker拉消息到本地队列,本地消费线程消费本地消息队列,异步过程,拉取线程不等待本地消费线程,这种模式实时性非常高
消费者本地队列内存大小保护,DefaultMQPushConsumer的pullThresholdForQueue属性,默认1000
轮询间隔
拉取线程多久一次?DefaultMQPushConsumer的pullInterval属性,默认0
消息消费数量
监听器每次接受本地队列多少条?DefaultMQPushConsumer的consumeMessageBatchMaxSize属性,默认1
消费进度存储
每隔一段时间将各队列消费进度存到对应broker,DefaultMQPushConsumer的persistConsumerOffsetInterval属性,默认5秒
一个topic在某broker有4个队列,一个消费者消费这4个队列,该消费者和这broker有几个连接?
一个,消费单位与队列相关,消费连接只跟broker相关
消费者将所有队列的消息拉取任务放到本地的队列,挨个拉取,拉取完毕后,又将拉取任务放到队尾,然后执行下一个拉取任务
生产者
与nameserver关系
连接
和一台NS保持长连接,定时查询topic配置信息,该NS挂掉,自动连下一个,直到有可用连接为止,自动重连
轮询时间
默认30秒从NS获取所有topic的最新队列情况,broker宕机,最多要30秒才感知,在此期间,发往该broker的消息发送失败。DefaultMQProducer的pollNameServerInteval参数
心跳
与NS没心跳
与broker关系
连接
和该生产者关联的所有broker长连
心跳
默认30秒向所有broker发心跳,DefaultMQProducer的heartbeatBrokerInterval参数
broker硬编码10秒扫所有存活连接,当前时间-最后更新时间>2分钟没心跳,关闭连接
连接断开
移除broker上的生产者信息
负载均衡
生产者之间没有关系,每个生产者向队列轮流发送消息
客户端与nameserver的连接关系
broker与所有NS长连,有变化,向所有NS发消息
但生产者和消费者只是跟某台NS保持联系
场景,某broker的topic配置发生变化,向所有NS发通知,但此某台NS推送失败(超时或者挂掉),NS集群之间的信息不完整,因为挂掉的那台NS没有得到最新变化
衍生三个问题:
1、如果该NS不是挂掉,只是瞬间没有响应,那可正常服务时,刚才那个borker发生的变化应该能生效,不应该被丢弃,否则nameserver之间的数据是不同步的
解决方案:broker定时向所有 NS 发自己的注册信息,当时某台 NS 挂掉重启或者超时,没关系,下次仍然会接受到上次没接收到的broker信息
2、真的挂了,但很快又恢复,因为borker和nameserver长连,显然挂掉重新启动后,broker与nameserver的长连接无效了,应该能自动重连
getAndCreateChannel()
3、只要某个nameserver不可用,消费者应该能failover,每次应该都检查长连接是否还有效,若无效则自动连接其他nameserver
getAndCreateNameserverChannel()
Priority
消息完全在内存队列,投递前可以按优先级排序后再投递
RMQ所有消息是持久化的,排序开销会非常大,通过变通,单独配多个队列, 不同优先级发送到不同队列即可
Order
RMQ 可严格保证消息有序,按发送顺序来消费
一个订单产生3条消息,订单创建,订单付款,订单完成
Filter
Broker端过滤
Broker按Consumer要求过滤,减少对Consumer无用消息网络传输 增加Broker负担,实现相对复杂
RMQ 按简单的Message Tag过滤,也支持Message Header、body过滤
Consumer端消息过滤
可由应用完全自定义实现,很多无用的消息要传输到Consumer端
Persistence
-
db
-
KV
-
文件,如Kafka,RMQ
-
内存数据做持久镜像
1.2.3 都具有将内存队列Buffer进行扩展的能力
4 只是内存镜像,Broker挂掉重启后仍然能将之前内存的数据恢复出来
JMS与CORBA Notification规范没有明确说明如何持久化,但这部分性能直接决定整个消息中间件的性能
RMQ充分利用Linux文件系统内存cache提高性能
Message Reliablity
- Broker正常关闭
- Broker异常Crash
- OS Crash
- 机器掉电,但是能立即恢复供电
- 机器无法开机(cpu、主板、内存等关键设备损坏)
- 磁盘损坏
1-4 都属硬件可立即恢复,RMQ 能保证消息不丢,或丢少量(同步还是异步刷盘)
5、6 单点故障,且无法恢复,一旦发生,此单点消息全部丢失
RMQ通过异步复制,保证99%消息不丢,仍会极少量可能丢失。同步双写可以完全避免单点,但势必影响性能,对消息可靠性要求极高的场合,例如Money相关
Low Latency
消息不堆积情况下,消息到达Broker后,能立刻到达Consumer
RMQ用长轮询Pull,保证消息非常实时,不低于Push
At least Once
每个消息必须投递一次 RMQ Consumer先pull消息到本地,消费完成后,才向服务器ack
没消费一定不会ack,所以可以很好的支持此特性
Exactly Only Once
- 发消息阶段,不允许发送重复
- 消费阶段,不允许消费重复消息
以上都满足情况下,才能认为消息是“Exactly Only Once”
分布式系统环境下实现以上两点,有巨大的开销。RMQ追求高性能,并不保证此特性,要求在业务上进行去重,消费消息要做到幂等性
正常情况下很少会出现重复发送、消费情况,只有网络异常,Consumer启停等异常情况下会出现消息重复
Broker的Buffer满了怎么办?
RMQ没内存Buffer概念,队列都持久化磁盘,数据定期清除
RMQ内存Buffer抽象成无限长度队列,不管有多少数据进来都能装得下
无限前提,Broker定期删除过期数据,默认Broker只存3天(72小时)消息,3天前数据从队尾删除
回溯消费
Consumer已经消费成功的消息,业务需要重新消费 RMQ支持按时间回溯消费,精确到毫秒,可向前回溯,也可向后回溯
定时消息
消息发到Broker后,不能立刻被Consumer消费,到特定时间点或等待特定时间后才能被消费
支持任意时间精度,Broker要做消息排序,再涉及到持久化,消息排序产生巨大性能开销
RMQ支持定时消息,但不支持任意时间精度,支持特定的level,例如定时5s,10s,1m等
消息重试
Consumer消费失败后,要提供重试机制,令消息再消费一次
- 消息本身,如反序列化失败,消息数据本身无法处理(话费充值,手机号被注销,无法充值)等。通常需要跳过这条消息,再消费其他消息,失败消息即使立刻重试消费,99%也不成功,最好定时重试,过10s秒后再重试
- 下游服务不可用,如db不可用,外系统网络不可达。即使跳过当前失败消息,消费其他消息同样也会报错。建议应用sleep 30s,再消费下一条消息,减轻Broker重试消息压力