HashTable HashMap
ddatsh
答案太多,抄篇不错的
HashTable于JDK 1.1,HashMap于JDK 1.2
HashMap作者多了Doug Lea
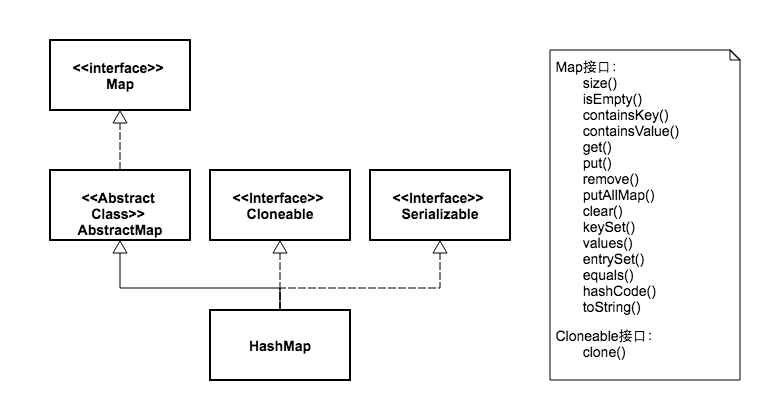
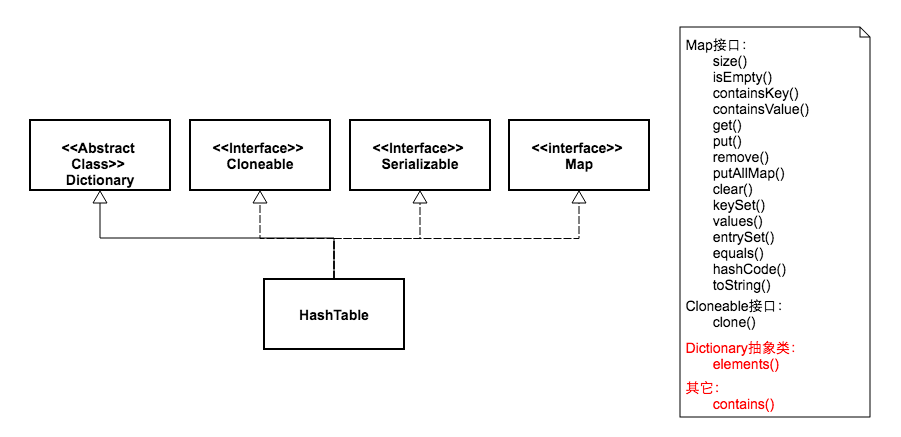
都实现Map、Cloneable、Serializable三个接口。Dictionary已废弃
Null Key & Null Value
HashMap 对null做了特殊处理,null的hashCode值定为0,存放在哈希表的第0个bucket
数据结构
内部用Entry数组实现哈希表,hash冲突时,用Entry链表来存储(解决hash冲突)
算法
HashTable默认初始大小11,每次扩充为原来的2n+1
HashMap默认始化大小16,每次扩充为原来的2倍
创建时给定大小,HashTable直接用给定大小,HashMap扩充为2的幂次方大小
HashTable尽量用素数、奇数。HashMap总用2的幂作哈希表大小
哈希表大小为素数,简单取模哈希的结果更均匀(余数的均匀分布,降低冲突率 ),单从这点上看,HashTable的哈希表大小选择,似乎更高明些
但取模计算,如果模数是2的幂,可直接用位运算得到结果,效率大大高于做除法。hash计算效率,又是HashMap更胜一筹
所以事实是HashMap为加快hash速度,将哈希表的大小固定为2的幂。引入哈希分布不均匀问题,HashMap为解决这问题,又对hash算法做一些改动
获取key对象的hashCode后,怎样将他们hash到确定的哈希桶(Entry数组位置)中?
HashMap用了2的幂次方,取模运算不需做除法,只需位的与运算。但hash冲突加剧,调用对象hashCode方法后,又做一些位运算再打散数据
HashMap和HashTable计算hash时都用到hashSeed变量。因为映射到同一个hash桶内的Entry对象,以链表形式存在,查询效率低,额外开启一个可选hash(hashSeed),减少哈希冲突
这个优化在JDK 1.8已经去掉,映射到同一个哈希桶(数组位置)的Entry对象,用红黑树存储,大大加速查找效率