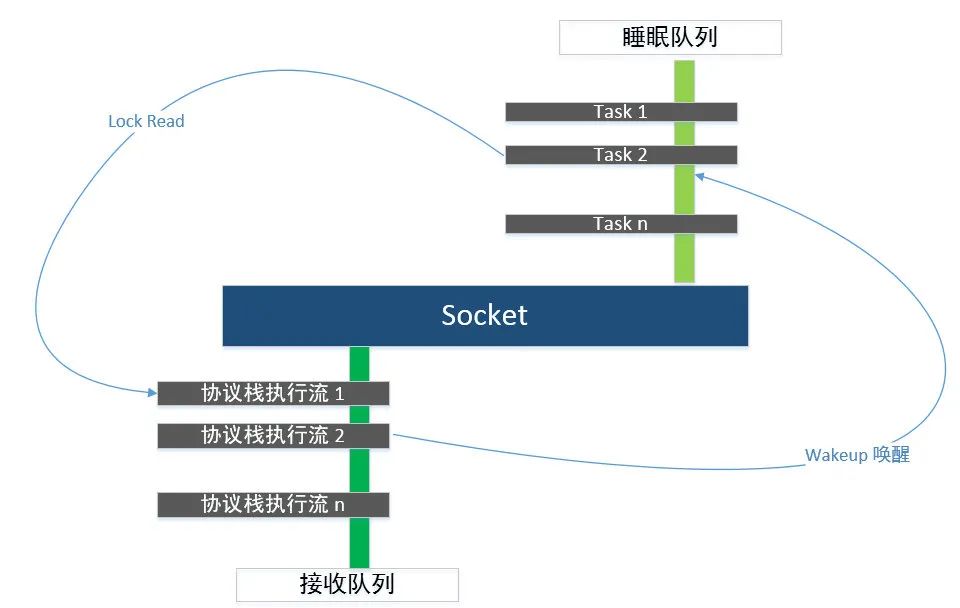
应用程序通过 socket 和协议栈交互,socket 隔离了应用程序和协议栈,socket 是两者之间的接口,对于应用程序,它代表协议栈;而对于协议栈,它又代表应用程序,当数据包到达协议栈的时候,发生下面两个过程:
- 协议栈将数据包放入socket的接收缓冲区队列,并通知持有该socket的应用程序
- 持有该socket的应用程序响应通知事件,将数据包从socket的接收缓冲区队列中取出
多个进程阻塞在 accept 调用,协议栈将 client 请求 socket 放入 listen socket 的 accept 队列的时,唤醒一个还是全部进程来处理?
古早linux 内核通过睡眠队列组织所有等待某个事件的 task,wakeup 机制可以异步唤醒整个睡眠队列上的 task,wakeup 逻辑在唤醒睡眠队列时,会遍历该队列链表上的每一个节点,调用每一个节点的 callback,从而唤醒睡眠队列上的每个 task
一个 connect 到达这个 lisent socket 时,内核会唤醒所有睡眠在 accept 队列上的 task
N 个 task 进程 (线程) 同时从 accept 返回,但只有一个 task 返回这个 connect 的 fd,其他 task 都返回 — 1(EAGAIN)。即典型的 accept"惊群" 现象
惊群消耗什么
-
系统对用户进程/线程频繁地做无效的调度,上下文切换系统性能大打折扣
直接的消耗包括 cpu 寄存器要保存和加载(例如程序计数器)、系统调度器的代码需要执行。间接的消耗在于多核 cache 之间的共享数据
-
为了确保只有一个线程得到资源,用户必须对资源操作进行加锁保护,进一步加大了系统开销
锁机制也会造成 cpu 等资源的消耗和性能损耗
常见的服务器有通过锁机制解决,比如 nginx(可关);还有些认为惊群对系统性能影响不大,没有去处理,比如 lighttpd
accept 惊群
主进程创建socket, bind, listen后,fork出多个子进程(为利用多核CPU)都循环处理(accept) 这个socket
之后内核 accept 阻塞调用加 WQ_FLAG_EXCLUSIVE(排他性的唤醒,即唤醒一个进程后即退出唤醒的过程) ,多个进程/线程都阻塞在对同一个 socket 的 accept 调用上时,新连接到来,内核只唤醒一个进程(新连接进入 accept 队列,内核唤醒且仅唤醒一个进程来处理),其他进程保持休眠,压根就不会被唤醒
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}#include <arpa/inet.h>
#include <assert.h>
#include <netinet/in.h>
#include <stdio.h>
#include <string.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#define SERVER_ADDRESS "0.0.0.0"
#define SERVER_PORT 10086
#define WORKER_COUNT 4
char sendbuff[1024];
int worker_process(int listenfd, int i) {
while (1) {
printf("I am work %d, my pid is %d, begin to accept connections \n", i, getpid());
struct sockaddr_in client_info;
socklen_t client_info_len = sizeof(client_info);
int connfd = accept(listenfd, (struct sockaddr *)&client_info, &client_info_len);
if (connfd != -1) {
printf("worker %d accept success\n", i);
printf("ip :%s\t", inet_ntoa(client_info.sin_addr));
printf("port: %d \n", client_info.sin_port);
snprintf(sendbuff, sizeof(sendbuff), "accept PID is %d\n", getpid());
send(connfd, sendbuff, strlen(sendbuff) + 1, 0);
// Process data or perform tasks with the connection
// ...
close(connfd);
printf("worker %d close success\n", i);
}
else {
printf("worker %d accept failed", i);
}
}
}
int main() {
int i;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
inet_pton(AF_INET, SERVER_ADDRESS, &address.sin_addr);
address.sin_port = htons(SERVER_PORT);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
// Add the SO_REUSEADDR option
int optval = 1;
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &optval, sizeof(optval));
setsockopt(listenfd, SOL_SOCKET, SO_REUSEPORT, &optval, sizeof(optval));
int ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address));
printf("bind ret=%d\n", ret);
ret = listen(listenfd, 5);
for (i = 0; i < WORKER_COUNT; i++) {
printf("Create worker %d\n", i + 1);
pid_t pid = fork();
/*child process */
if (pid == 0) {
worker_process(listenfd, i);
}
if (pid < 0) {
printf("fork error");
}
}
//wait child process
int status;
wait(&status);
return 0;
}strace -f可观测到accept不存在惊群
select/poll/Epoll 惊群
select,poll,epoll 等事件模型更为受到欢迎,所谓的事件模型即阻塞在事件上而不是阻塞在事务上
内核仅仅通知发生了某件事,具体发生了什么事,则由处理进程或者线程自己来 poll
事件模型可以一次搜集多个事件,从而满足多路复用的需求
几种多路复用技术利用多核 CPU,会起多个进程 (线程) 同时提供服务
如果多个进程/线程阻塞在监听同一个 listening socket fd 的 epoll_wait 上,当有一个新的连接到来时,多个子进程被唤醒
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/epoll.h>
#include <netdb.h>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/wait.h>
#define PROCESS_NUM 10
#define MAXEVENTS 64
static int create_and_bind(char* port) {
int fd = socket(PF_INET, SOCK_STREAM, 0);
struct sockaddr_in serveraddr;
serveraddr.sin_family = AF_INET;
serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);
serveraddr.sin_port = htons(atoi(port));
bind(fd, (struct sockaddr *)&serveraddr, sizeof(serveraddr));
return fd;
}
static int make_socket_non_blocking(int sfd) {
int flags, s;
flags = fcntl(sfd, F_GETFL, 0);
if (flags == -1) {
perror("fcntl");
return -1;
}
flags |= O_NONBLOCK;
s = fcntl(sfd, F_SETFL, flags);
if (s == -1) {
perror("fcntl");
return -1;
}
return 0;
}
int main() {
int sfd, s;
int efd;
struct epoll_event event;
struct epoll_event* events;
sfd = create_and_bind("8888");
if (sfd == -1) {
abort();
}
s = make_socket_non_blocking(sfd);
if (s == -1) {
abort();
}
s = listen(sfd, SOMAXCONN);
if (s == -1) {
perror("listen");
abort();
}
efd = epoll_create(MAXEVENTS);
if (efd == -1) {
perror("epoll_create");
abort();
}
event.data.fd = sfd;
// event.events = EPOLLIN | EPOLLET;
event.events = EPOLLIN;
s = epoll_ctl(efd, EPOLL_CTL_ADD, sfd, &event);
if (s == -1) {
perror("epoll_ctl");
abort();
}
/* Buffer where events are returned */
events = calloc(MAXEVENTS, sizeof event);
int k;
for (k = 0; k < PROCESS_NUM; k++) {
int pid = fork();
if (pid == 0) {
/* The event loop */
while (1) {
int n, i;
n = epoll_wait(efd, events, MAXEVENTS, -1);
printf("process %d return from epoll_wait!\n", getpid());
/* sleep here is very important!*/
// sleep(2);
for (i = 0; i < n; i++) {
if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) || (!(events[i].events & EPOLLIN))) {
/* An error has occured on this fd, or the socket is not
ready for reading (why were we notified then?) */
fprintf(stderr, "epoll error\n");
close(events[i].data.fd);
}
else if (sfd == events[i].data.fd) {
/* We have a notification on the listening socket, which
means one or more incoming connections. */
struct sockaddr in_addr;
socklen_t in_len;
int infd;
char hbuf[NI_MAXHOST], sbuf[NI_MAXSERV];
in_len = sizeof in_addr;
infd = accept(sfd, &in_addr, &in_len);
if (infd == -1) {
printf("process %d accept failed!\n", getpid());
break;
}
printf("process %d accept successed!\n", getpid());
/* Make the incoming socket non-blocking and add it to the
list of fds to monitor. */
close(infd);
}
}
}
}
}
int status;
wait(&status);
free(events);
close(sfd);
return EXIT_SUCCESS;
}telnet localhost 8888process 545913 return from epoll_wait!
process 545912 return from epoll_wait!
process 545913 accept successed!
process 545912 accept failed!
process 545911 return from epoll_wait!
process 545911 accept failed!看上去是只有 3 个进程唤醒了,而事实上,其余进程没有被唤醒的原因是某个进程已经处理完这个 accept,内核队列上已经没有这个事件,无需唤醒其他进程。在 epoll 获知这个 accept 事件的时候,不要立即去处理,而是 sleep 下,这样所有的进程都会被唤起
再测试,所有的进程都被唤醒了
为什么内核不处理 epoll 惊群
accept 应该只能被一个进程调用成功,内核很清楚这一点
但 epoll 监听的fd,除可能被 accept 调用外,还有可能是其他非 socket IO 事件的
其他 IO 事件是否只能由一个进程处理(如一个文件会由多个进程来读写),得用户决定,内核不能强制
Linux epoll 的实现机制
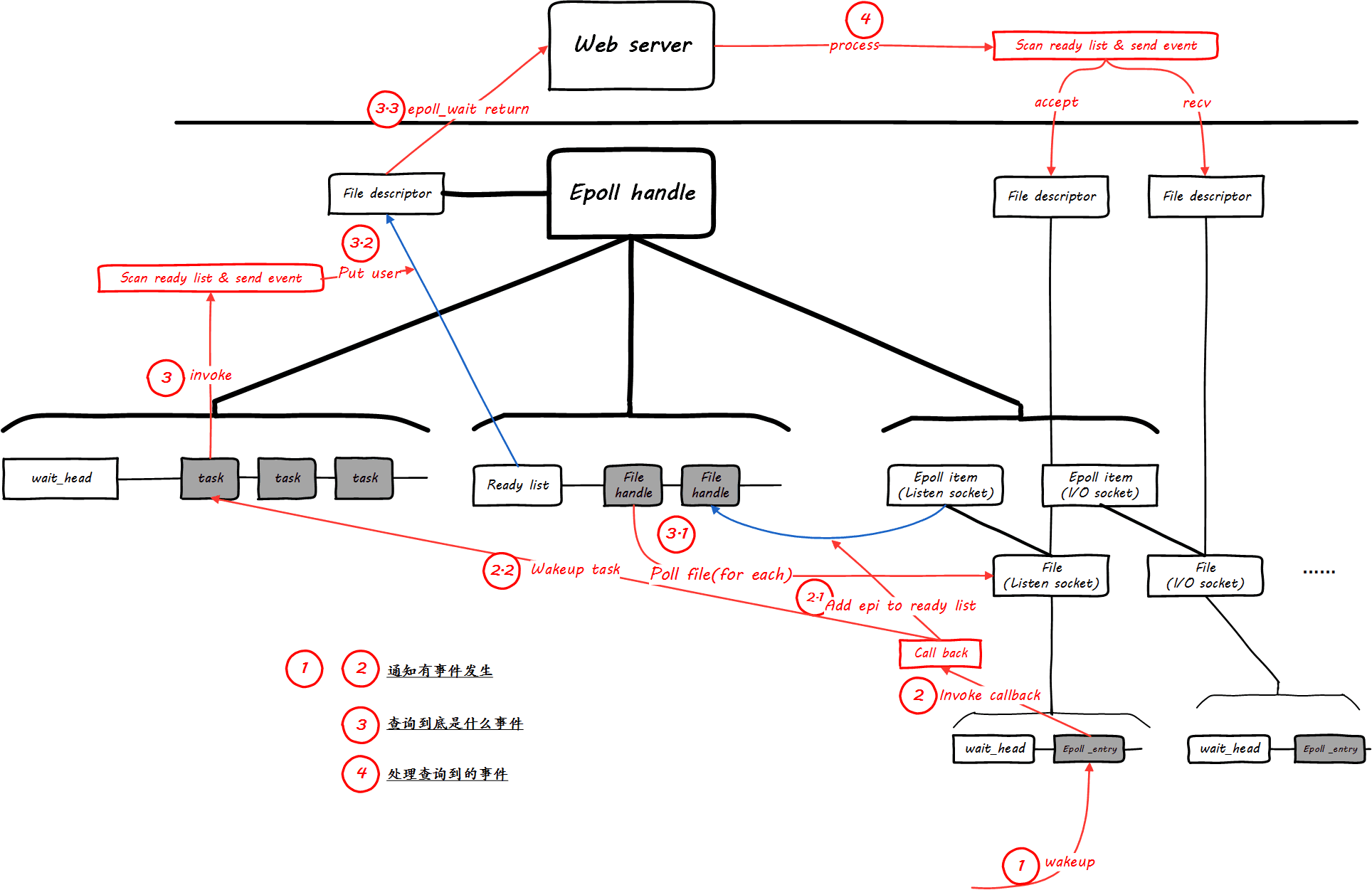
- 创建 epoll 句柄,初始化相关数据结构
// fs/eventpoll.c 精简
struct eventpoll {
// 阻塞在epoll_wait的task的睡眠队列
wait_queue_head_t wq;
// 存在就绪文件句柄的list,该list上的文件句柄事件将会全部上报给应用
struct list_head rdllist;
// 存放加入到此epoll句柄的文件句柄的红黑树容器
struct rb_root rbr;
// 该epoll结构对应的文件句柄,应用通过它来操作该epoll结构
struct file *file;
};- 为 epoll 句柄添加文件句柄,注册睡眠 entry 的回调
将一个文件句柄,比如 socket 添加到 epoll 的 rbr 红黑树容器中
struct epitem {
// 该字段链接入epoll句柄的红黑树容器
struct rb_node rbn;
// 当该文件句柄有事件发生时,该字段链接入“就绪链表”,准备上报给用户态
struct list_head rdllink;
// 封装实际的文件
struct epoll_filefd {
struct file *file;
int fd;
} ffd;
// 反向指向其所属的epoll句柄
struct eventpoll *ep;
};注册睡眠 entry 回调并 poll 文件句柄
Linux 内核的 sleep/wakeup 机制几乎贯穿了所有的内核子系统,不限制睡眠的 entry 一定要是一个 task,将睡眠的 entry 做了一层抽象,即:
struct __wait_queue {
unsigned int flags;
// 至于这个private到底是什么,内核并不限制,显然,它可以是task,也可以是别的。
void *private;
wait_queue_func_t func;
struct list_head task_list;
};这个 entry,最终要睡眠在下面的数据结构实例化的一个链表上:
struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};文件句柄有自己睡眠队列用于等待自己发生事件的 entry 在没有发生事件时来歇息,TCP socket 睡眠队列就是其 sk_wq,通过以下方式取到:
static inline wait_queue_head_t *sk_sleep(struct sock *sk){
return &rcu_dereference_raw(sk->sk_wq)->wait;
}lighttpd 解决思路:无视惊群
Watcher/Worker 模式,优化了 fork() 和 epoll_create() 的位置(让每个子进程自己去epoll_create()和 epoll_wait()),主动捕获 accept() 抛出的错误并忽视
nginx 解决思路:避免惊群
Nginx 使用全局互斥锁,每个工作进程在 epoll_wait() 之前先去申请锁,得到锁了才继续处理,得不到锁则等待,并设置了一个负载均衡算法来权衡各个进程的任务量(当某个工作进程的任务里达到总设置量的 7/8 时,不再尝试去申请锁)
首先启动进程的时候,不把 listenfd 加入自己的 epoll 中,等待进程初始化完毕,开始处理事件的时候,这时候的第一步就是抢锁,即抢占对 listenfd 的控制权,哪个进程抢到,立刻加入自己的 epoll。没抢到的进程继续自己的处理,但是不会 accept 抢到 listenfd 的进程,就会 accept 新的连接
这个锁是 自旋锁 用原子变量实现的 不会造成进程的睡眠和阻塞
Leader/Followers 线程模式
各个线程地位平等,轮流做 Leader 来响应请求
epoll 的实现中,每次 epoll_ctl/add/del 的时候,通过 ep_modify/insert/unlink/remove 实现,操作中先调用 spin_lock 和获得读写锁,所以在用户态中 epoll 是无锁编程,线程安全的,在内核态中是有锁的。也就是说,即使惊群,也还是安全的
Linux 4.5
提供了 EPOLL_EXCLUSIVE ,在 TCP 三次握手最后一个 ACK 报文调用 sock_def_readable 时只唤醒一个等待源,这样就在内核层面避免了 “惊群” 问题了