阅读代码是很好的锻炼耐心和毅力的机会
看别人代码的过程,即针对一个疑问,收集线索,有点连成线的过程,中间肯定有一段时间非常难熬与枯燥
完所有的代码,所有的线索都连成一条线,就能体会柳暗花明了
并不是说阅读了大量的代码就能写出很牛的代码,写代码需要对当前需求的把握和清晰的逻辑思维,实践中可以慢慢培养。千万不要读得太多,而写得太少
不在浮沙筑高台
并不推荐一上来就是看源码,一般在某个方向上有一定的基本知识积累了才开始去尝试阅读
c 服务器的后台代码,需要对 linux 网络/系统编程有一定的认识,甚至读过 W.Richard Stevens 的几本经典之作。完全的新人去阅读代码,只会信心受打击
初学者在某一技术方向上有基本的积累后,找一个优秀的开源项目试着阅读
网上很多的资料以及文档,为读懂源码提供很多的帮助
见识业界的编程规范,优秀的框架或者模式,前人在大量的实践中总结出来的,必定是行而有效的,夯实在某个技术方向上的认知
练就你的耐心和毅力
阅读源码本身是枯燥乏味的过程,经常看一个模块一两天,来来回回往往复复,假使心浮气躁,容易浅尝辄止,半途而废
如何阅读 Redis 源码?
一、数据结构实现
和其他部分耦合最少, 数据结构算法书上都可了解到, 读最轻松、难度最低
| 文件 | 内容 |
|---|---|
| sds.h、sds.c | 动态字符串 |
| adlist.h、adlist.c | 双端链表 |
| dict.h、dict.c | 字典 |
| redis.h zskiplist 和 zskiplistNode 结构, t_zset.c zsl 开头的函数,如 zslCreate 、 zslInsert 、 zslDeleteNode 等 | 跳跃表 |
| hyperloglog.c 中 hllhdr 结构, hll 开头的函数。 | HyperLogLog |
二、内存编码数据结构
Redis 为了节约内存而专门开发,数据结构都是特制(adhoc)的
基本都和内存分配、指针操作、位操作这些底层的东西有关
| 文件 | 内容 |
|---|---|
| intset.h 和 intset.c | 整数集合(intset) |
| ziplist.h 和 ziplist.c | 压缩列表(zip list) |
三、数据类型实现
| 文件 | 内容 |
|---|---|
| object.c | 对象(类型)系统实现 |
| t_string.c | 字符串键 |
| t_list.c | 列表键 |
| t_hash.c | 散列键 |
| t_set.c | 集合键 |
| t_zset.c 中除 zsl 开头的函数之外的所有函数 | 有序集合键 |
| hyperloglog.c 中所有以 pf 开头的函数 | HyperLogLog 键 |
四、数据库实现
| 文件 | 内容 |
|---|---|
| redis.h 中 redisDb 结构, db.c | 数据库实现 |
| notify.c | 数据库通知功能 |
| rdb.h 和 rdb.c | RDB 持久化 |
| aof.c | AOF 持久化 |
其他
| 文件 | 内容 |
|---|---|
| redis.h 的 pubsubPattern 结构,pubsub.c 文件。 | 发布与订阅 |
| redis.h 的 multiState 及 multiCmd 结构, multi.c | 事务 |
| sort.c | SORT |
| bitops.c | GETBIT 、 SETBIT 等二进制位操作 |
五、客户端和服务器
| 文件 | 内容 |
|---|---|
| ae.c ,及ae_*.c (多路复用库) | 事件处理器实现(基于 Reactor 模式) |
| networking.c | 网络连接库,负责发送命令回复和接受命令请求, 同时也负责创建/销毁客户端, 以及通信协议分析等工作 |
| redis.h 和 redis.c 中和单机 Redis 服务器有关的部分 | 单机 Redis 服务器的实现 |
其他
| 文件 | 内容 |
|---|---|
| scripting.c | Lua |
| slowlog.c | 慢查询 |
| monitor.c | 监视器 |
六、多机功能
| 文件 | 内容 |
|---|---|
| replication.c | 复制功能 |
| sentinel.c | Sentinel |
| cluster.c | 集群的实现 |
Sentinel 用到复制功能, 而集群又用到了复制和 Sentinel,先阅读复制模块, 然后Sentinel 模块, 最后才阅读集群模块
http://blog.huangz.me/index.html
用户关系模块, “共同关注”功能, 计算出两个用户关注了哪些相同的用户,打印类似“你跟 john 都关注了 peter 和 tom ”
从集合计算的角度来看, 共同关注功能本质上就是计算两个用户关注集合的交集
要计算两个集合的交集, 除了需要对两个数据表执行合并(join)操作之外, 还需要对合并的结果执行去重复(distinct)操作, 交集操作的实现是否会变得异常复杂?性能如何?
MYSQL 只有并集没有交集差集关键字
表结构 a
| name | id |
|---|---|
| a3 | 4 |
| a1 | 1 |
| a2 | 2 |
| a3 | 3 |
b
| name | id | aid |
|---|---|---|
| b1 | 1 | 1 |
| b2 | 2 | 1 |
| b3 | 3 | 0 |
并集
UNION 不包含重复数据
SELECT NAME FROM a UNION SELECT NAME FROM b;
a3 a1 a2 b1 b2 b3
UNION ALL 包含重复数据
差集
找出在a表中存在的id 但是在b表中不存在的id
利用 union
|
|
子查询 not in
|
|
子查询 not exists
|
|
左连接判断右表IS NULL
|
|
交集 INTERSECT :
|
|
用 Redis 重写之后关系模块代码量更少, 速度更快, 之前需要使用一段甚至一大段 SQL 查询才能实现的功能, 现在只需要调用一两个 Redis 命令就能够实现了, 整个模块的可读性得到了极大的提高
Redis 3.0 更新主要与多机功能有关,单机功能与2.6、2.8基本相同
SDS
C 字符串 \0结尾,Redis 自己构建了简单动态字符串(simple dynamic string,SDS)的抽象类型, 用作 Redis 的默认字符串表示
C 字符串只会作为字符串字面量(string literal), 用在一些无须对字符串值进行修改的地方, 比如打印日志:
redisLog(REDIS_WARNING,“Redis is now ready to exit, bye bye…”);
|
|
键也是一个SDS对象, “msg”
SDS还用在缓冲区: AOF 缓冲区、client 输入缓冲
sds.h/sdshdr
|
|
SDS 同样遵循 C 字符串以 \0 结尾, \0的 1 字节不计算在len 属性里
遵循 \0 结尾的好处是, SDS 可以直接重用一部分 C 字符串函数库函数
SDS 指针 s ,可以直接使用 stdio.h/printf 函数
|
|

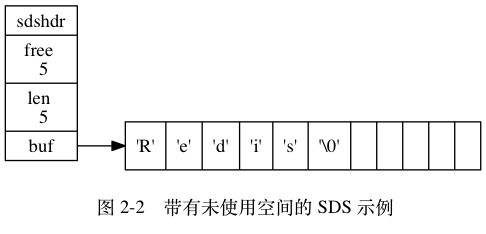
图2为 buf 数组分配了五字节未使用空间 , free = 5
SDS 与 C 字符串的区别
- O(N), O(1) C 字符串表示方式, 不能满足 Redis 对字符串安全性、效率、功能的要求
C不记录字符串长度,获取长度要遍历到 \0,复杂度O(N),redis O(1),如STRLEN
设置和更新 SDS 长度由 SDS 的 API 在执行时自动完成
所以SDS,是一个经典的用空间换取时间效率的实现
- 杜绝缓冲区溢出
|
|
|
|
SDS 的空间分配策略杜绝了发生缓冲区溢出的可能性: SDS API先检查空间, 不够,自动扩展,使用 SDS 不需要手动修改 SDS 空间大小, 也不会缓冲区溢出
- 减少内存重分配
C 不记录字符串长度,append要重分配,忘了会缓冲区溢出
trim要重分配,忘了会内存泄露
redis速度要求苛刻,数据修改频繁,通过未使用空间, SDS 实现了空间预分配和惰性空间释放两种优化策略
空间预分配
- SDS修改后,长度 < 1MB,分配和 len同样大小的未使用空间,此时 free==len
- 长度 >1MB,分配1MB未使用时间
如SDS修改后,len=13, 那会分配 13 字节未使用空间, buf 长度=13 + 13 + 1 = 27 字节(额外的一字节 \0)
SDS len =30 MB , 分配 1 MB 未使用空间, buf 数组的实际长度将为 30 MB + 1 MB + 1 byte
通过这种预分配策略, SDS 将连续增长 N 次字符串所需的内存重分配次数从必定 N 次降低为最多 N 次
惰性空间释放
SDS API 需要缩短字符串时, 不立即内存重分配回收,用 free 属性将这些字节的数量记录起来, 并等待将来使用
SDS 也提供了真正地释放未使用空间的API
二进制安全
SDS根据len判断是否结束
兼容部分c函数
还有比如strcmp
源码
redis 3.2 数据结构变更,增强
|
|
sdshdr8/16/32/64
针对不同长度字符串优化,不同数据类型uint8/16_t等表示长度、申请字节大小等
attribute ((packed)) 告诉编译器取消字节对齐,结构体的大小就是按照结构体成员实际大小相加得到的
链表
节点重排, 顺序性节点访问,增删节点调整长度
发布与订阅、慢查询、监视器等
多个客户端的状态信息,构建客户端输出缓冲区
adlist.h/listNode 双端链表
|
|
adlist.h/list
head 、tail , 链表长度 len , 多态链表函数 dup 、 free 和 match
双端: prev next 指针, 前后置节O(1) 无环: 表头prev 和表尾next 指针指向 NULL , 链表访问以 NULL 为终点 表头和表尾指针:头尾节点 O(1) 链表长度计数器: 节点数量O(1) 多态: 链表节点使用 void* 指针来保存节点值, 并且可以通过 list 结构的 dup 、 free 、 match 三个属性为节点值设置类型特定函数, 所以链表可以用于保存各种不同类型的值
字典
redis用的是MurmurHash2
hash键冲突用链地址法解决
rehash
扩展,收缩后,渐进式rehash,逐步轮转 ht[0] ht[1]
渐进式 rehash 过程中
字典同时使用 ht[0] 和 ht[1] ,curd会在两个哈希表上进行: find 先在 ht[0] 查找, 没找,继续到 ht[1]
新键值保存到 ht[1] , 保证 ht[0] 只减不增, 随 rehash执行而最终变成空表
BGSAVE 或 BGREWRITEAOF,Redis fork出子进程 & cow 优化子进程使用效率来操作,是否正在执行, 服务器执行扩展操作所需的负载因子并不相同, 尽可能地避免在子进程存在期间进行哈希表扩展操作, 避免不必要的内存写入操作, 最大限度地节约内存
跳跃表
有序集合键 ( 带score的键)
集群节点内部数据结构
http://blog.csdn.net/androidlushangderen/article/details/39803337
https://github.com/linyiqun/Redis-Code
http://redissrc.readthedocs.io/en/latest/datastruct/sds.html
http://blog.huangz.me/index.html
http://wiki.jikexueyuan.com/project/redis/built-towers.html
http://tonybai.com/2013/03/07/struct-hack-in-c/
http://zcheng.ren/2016/12/02/TheAnnotatedRedisSourceSDS/