基本概念、复制原理、配置不同类型的复制
GTID 复制、半同步复制、动静分离,5.7 组复制 (MGR)
基本概念和原理
从 master 将数据通过日志的方式经过网络传送到另一台或多台salve,然后在 slave 上重放 (replay 或 redo) ,以达到和 master 数据同步的目的
初始change master to 设置连 master 参数,记到 slave datadir\master.info,relay-log.info
IO 线程连接 master(启动 dump 线程),接master 的 binlog,复制写入到自己的中继日志 (relay log)
SQL 线程监控、读取并重放 relay log,数据写入到自己的数据库


同步复制\半同步复制\异步复制\延迟复制



5.6
引入GTID,server uuid(auto.cnf)和事务ID组成
并行只基于库(Schema)
- Crash Safe 不好做,可能后执行的事务由于并行复制先完成执行
- 性能不高单库多表比多库多表更常见
基于GTID的Replication好处
传统复制
发生故障后,主从切换,需找到binlog和pos点,然后change master to指向新的master,麻烦易错
GTID后只需要知道master ip,port,自动找点同步
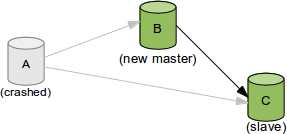
A 宕机,需要切到 B上。同时又需要将C的复制源改成B
|
|
难点在于,同一个事务在每台机器上所在的binlog名字和位置都不一样,怎么找到C当前同步停止点,对应B的master_log_file和master_log_pos是什么
M-S复制集群需要使用 MMM/MMA 这样的额外管理工具的一个重要原因
多线程复制(基于库) MGR
5.6基于库
5.7基于表(真正意义上多线程复制)
slave-parallel-type
- DATABASE:默认值,基于库的并行复制方式
- LOGICAL_CLOCK:基于组提交的并行复制方式(
last_committed和sequence_number)
binlog 字段 last_committed 和 sequence_number
下一个事务在主库配置好组提交以后,last_committed 和上一个事务的 sequence_number 相等,因为事务是顺序提交的
最后两个事务的 last_committed 相同,意味着这两个事务作为一个组提交,两个事务在 Perpare 阶段获取相同的 last_committe 而且相互不影响,最终是会作为一个组进行提交
组提交是并行复制的基础
组提交的事务可以在slave并行回放
master
- binlog_group_commit_sync_delay
全局动态变量,单位微妙,默认 0,范围:0~1000000(1秒)
binlog提交后等待延迟多少时间再同步到磁盘,默认0 ,不延迟0 以上时,允许多个事务的日志同时一起提交,就是组提交。组提交是并行复制的基础,大于 0 就代表打开了组提交的功能
- binlog_group_commit_sync_no_delay_count
全局动态变量,单位个数,默认 0,范围:0~1000000
等待延迟提交的最大事务数,如果上面参数的时间没到,但事务数到了,则直接同步到磁盘。若
binlog_group_commit_sync_delay没有开启,则该参数也不会开启
slave
|
|
MGR不是强同步的,但是最终会一致的
确切的说:事务会按照相同的顺序发送给这个group的所有成员,但是事务的执行、commit完全由成员自行处理,并不是同步进行的
Group Replication Limitations
MGR在GTID基础上构建,GTID的限制不能使用event的checksums
|
|
Gap locks , 建议设置隔离级别为 READ COMMITTED
|
|
SERIALIZABLE , MGR不支持SERIALIZABLE隔离级别
- 并发DDL和DML在同一个对象上的操作,会有问题
|
|
-
外键级联约束
-
大事务
|
|
- multi-primary的死锁检测
|
|
- 复制过滤
|
|
FAQ
MGR成员数量最大9个
MGR来scale-out写压力
a)并不是直接的扩展方式,每一个成员都有完整的数据copy
b)但是其他server并不是做完全一样的写动作,MGR通过ROW模式复制,其他server只需要apply row即可,并不是re-executed事务了,因此会快且压力小很多
c)更进一步讲,row-based应用都是经过压缩过的,可以减少很多IO动作,相比master上的执行压力会小很多的
d)总结,可以scale-out写,在没有写冲突事务的时候在多台服务器上执行事务是可以做到scale-out的
如果网络临时有问题,组成员会自动重新加入group吗
取决于是什么网络问题 短暂,瞬间,MGR错误检测机制根本还没来得及探测到此问题,该成员不会被移除出组 长时间问题,错误检测机制最终会认为它除了问题,将此server移除出组
一旦移除出组,需要让他重新加入一次,换句话说,需要手工来处理,或用脚本来自动处理
如果一个节点严重延迟,会产生什么问题
没有一个很好的策略来自动判断什么时候去驱逐一个成员 需要找到为什么它会延迟,并解决它,或移除它 否则,当一个server慢到触发流控,然后整个group都会变的慢下来