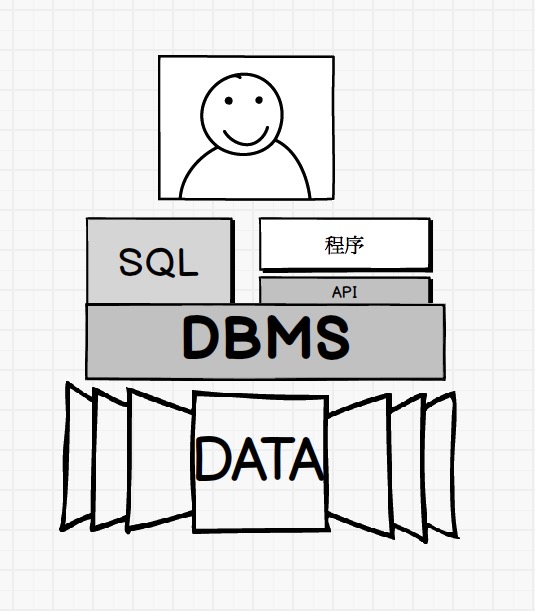
数据库的东西,往往一个参数就牵涉N多知识点
扩展
业务规模越来越大,就会遇到扩展这个问题
一般有两个选择:
- scale up 向上扩展,垂直扩展
针对服务器进行硬件上的提升,是一个非常不理想的扩展方式
- 硬件水平提升代价太大
- 性能只能提升到某个程度
- scale out 向外扩展,水平扩展
这种扩展方式是增加服务器,架设集群
- 花费的代价小
- 性能提升大
- 如果之前是单服务器,现在组成集群还可以实现业务的高可用
用廉价的X86组成高性能,高可用集群
Replication
MySQL集群基本是由复制功能实现的
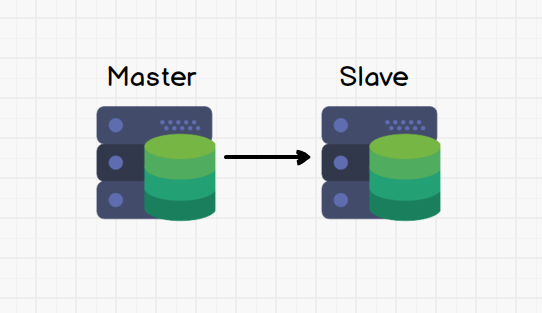
- 一主一从 Master to Slave
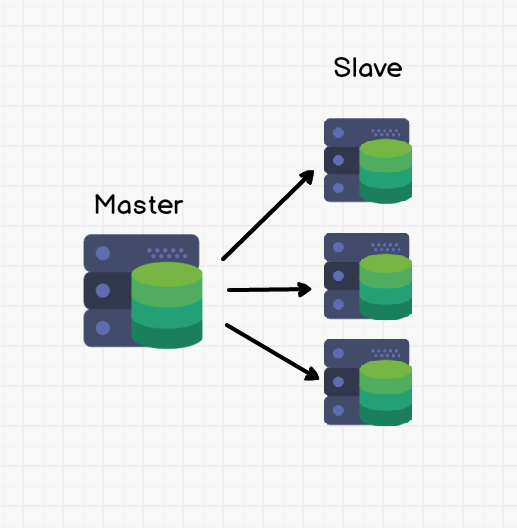
- 一主多从 Master to Multiple Slaves
- 双主模型 Multi—Master
-
多级复制 Master to Slave(s) to Slave(s)
-
环状模型 Multi—Master Ring

MySQL主从同步复制复制原理
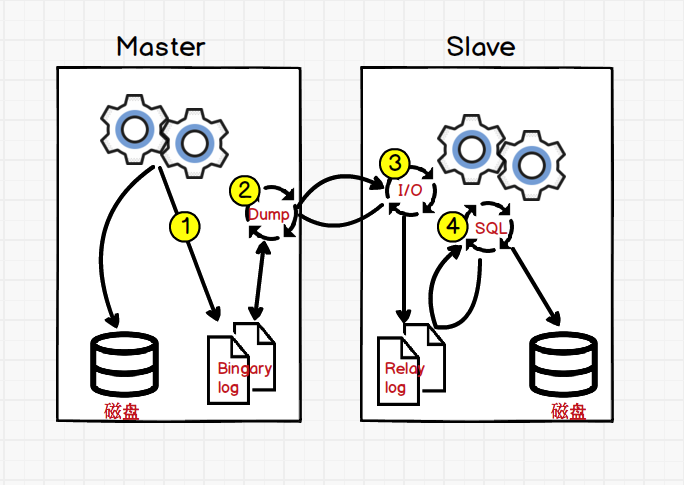
MySQL除数据文件还有其他日志文件,比说事务日志,慢查询日志
Bingary log(二进制日志)也是其中一种,将DML(select除外)、DDL记录其中,且可以被修改和重放,作用很大。增量备份和复制都要用到
Relay log(中继日志)其实就是Slave将Master的Bingary log日志复制过来。然后在Slave中存下来,就叫做中继日志
- 数据修改写入盘同时,还写入Bingary log
- Dump:binlogdump,将Slave I/O thread请求的资源发送给对方,所以Dump叫二进制转储线程,也叫做倾倒线程
- I/O thread,从Master取回Bingary log存储到Relay log中。I/O thread并不是轮询状态,为了节省资源,I/O thread是由Master唤醒的
- SQL thread,读取Relay log的内容,并重放
这图对应最简单的主从同步,多级复制也差不多这样,只是Slave也开启了Bingary log
Master-Slave模型
最常见的模型之一,包括一主多从架构
优点
一或多个从降低读压力,大大提升性能。特别是读多写少的场景,需要前端有读写分离器来完成
缺点
- 一主模型主永远都是单点故障点,主宕机,从可能数据丢失(同步复制或GTID来快速同步),数据量大时,单线程复制不能迅速将完成对资源快速复制。Master宕机后,整个系统还无法响应写请求
半同步复制
Google回馈给MySQL的插件,能实现主从架构中,手动指定哪些Slave同步复制,哪些异步复制,就可实现和Master同机房的Slave用同步复制Master的数据
other
Multi-Master,直接互为主从,会出问题的情况:
一个服务器将col2的值当条件对col1的值进行处理
|
|
而另一个服务器却正在用col1的值对col2进行操作
|
|
这个时候就会出现数据不一致的情况
redo/undo/bin log
innodb支持事务,redo log和undo log都是innodb的产物
binlog也可以用作数据恢复,不过它是整个mysql的日志,对于所有存储引擎都生效
binlog存储的是逻辑sql,这一点与redo log中的物理格式不同
binlog在事务结束后才写进文件,redo log在事务执行中写进文件
Write-Ahead Logging
解决据写入时io瓶颈带来的性能问题
修改db数据时,先将数据从磁盘读到内存进行修改,并将修改行为持久化到事务日志(先写redo log buffer,再定期批量写入)
事务日志持久化完成后,内存脏数据可慢慢刷回磁盘
事务日志追加写入,顺序io性能优势更好
即是redo log
避免脏数据刷回磁盘过程中,掉电或系统故障带来的数据丢失问题
用于在实例故障恢复时,继续那些已经commit但数据尚未完全回写到磁盘的事务
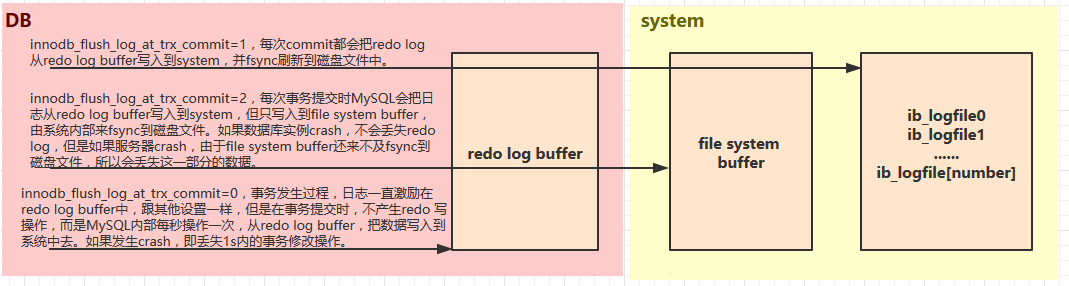
redo 参数
其中的
- innodb_flush_log_at_trx_commit
并发参数
innodb_thread_concurrency
默认是0 不限制并发线程数,所有请求直接请求线程执行
db 没出现性能问题时,使用默认值即可
大于0,检查当前并发线程数是否达到上限,有,sleep一段时间(5.7自动)后再次请求
再次,当前并发数还上限,进FIFO队列
当线程进入内核执行时,得到一个 ticket(默认5000)避免重复检查步骤,次数消费完,线程被驱逐,等待下次再次进入Innodb,再重新分配ticket
官网建议配置
- 并发用户线程数量<64,设 0
- 负载不稳定,时高时低,先从128降,96, 80, 64等,直到发现能够提供最佳性能的线程数,如,假设通常40到50个用户,但定期的数量增加至60,70,甚至200。发现在80个并发用户设置时表现稳定,如果高于这个数,性能反而下降。就 80
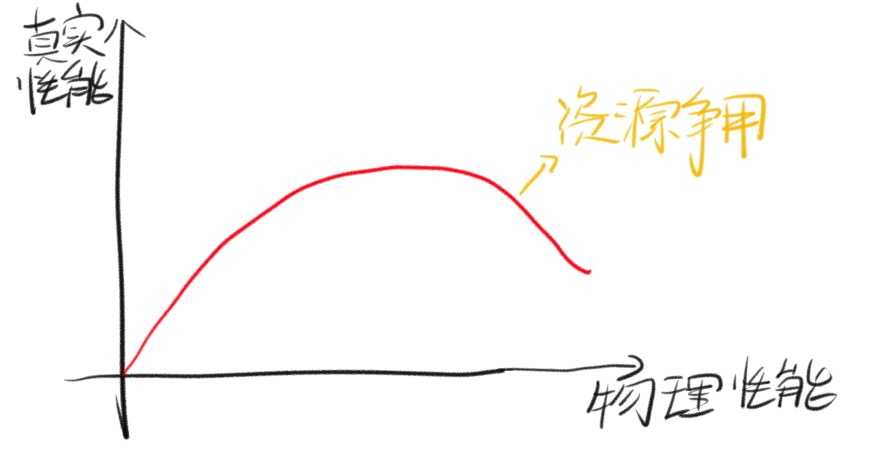
- 过高可能因系统资源内部争夺导致性能下降
- 多数情况下,最佳值是小于并接近虚拟CPU的个数
- 定期监控和分析DB,随着负载变化,业务的增加,innodb_thread_concurrency也需要动态的调整