RPC :数据编码(内存对象与可传输的字节流 转化),请求映射
数据编码
XML 日薄西山,JSON 风头正盛,Protobuf 方兴未艾
why Protobuf ?谷歌出品,某些场景下效率比 JSON 高
所有的优化都是有代价的。思考选择什么和放弃什么
RPC :数据编码(内存对象与可传输的字节流 转化),请求映射
XML 日薄西山,JSON 风头正盛,Protobuf 方兴未艾
why Protobuf ?谷歌出品,某些场景下效率比 JSON 高
所有的优化都是有代价的。思考选择什么和放弃什么
二进制数据,每个字符取值范围[0, 255],作为ascii码解析时,只有部分可显示(打印)
肉眼查看/作为文本拷贝这份数据,16进制优于二进制ascii码格式
但16进制表示法需两个字节才能表示表示原始数据的一个字节,即大小增加了一倍
base64算法保持编码后可打印特性的同时,大小只增加 1/3
“接口+策略模式+配置文件” 组合实现的动态加载机制
SPI 应用之一是可替换的插件机制
定义一组接口
写接口的一个或多个实现
src/main/resources/META-INF/services/接口名文件, 内容是要应用的实现类
用 ServiceLoader 加载配置文件中指定的实现
主要被框架的开发人员使用,如 java.sql.Driver 接口,不同厂商可以针对同一接口做出不同的实现
解决并发事务互相干扰问题,MySQL 事务隔离级别:
基本概念、复制原理、配置不同类型的复制
GTID 复制、半同步复制、动静分离,5.7 组复制 (MGR)
适合单线程程序,多线程需要保护getInstance(),否则可能产生多个Singleton对象实例
|
|
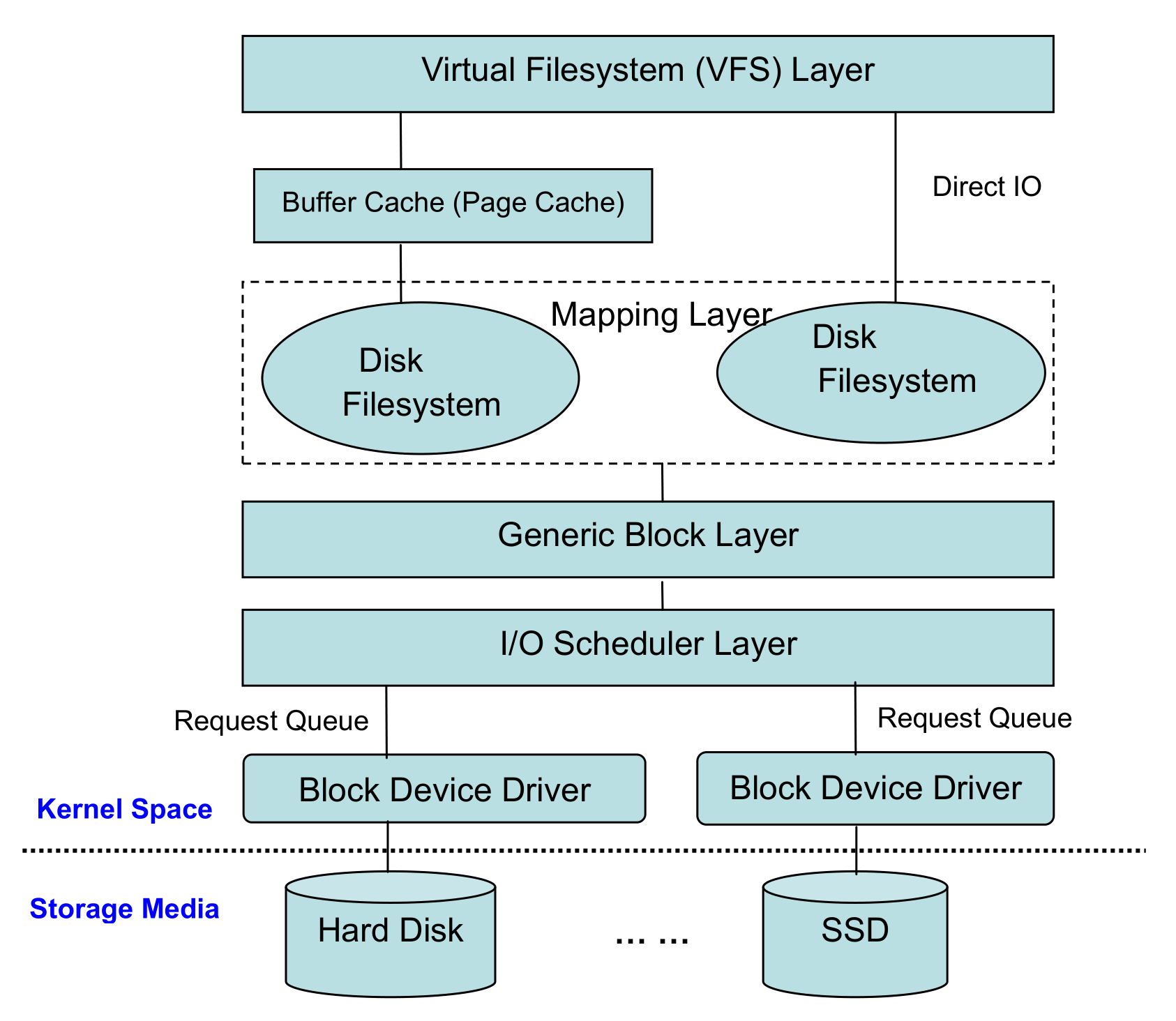
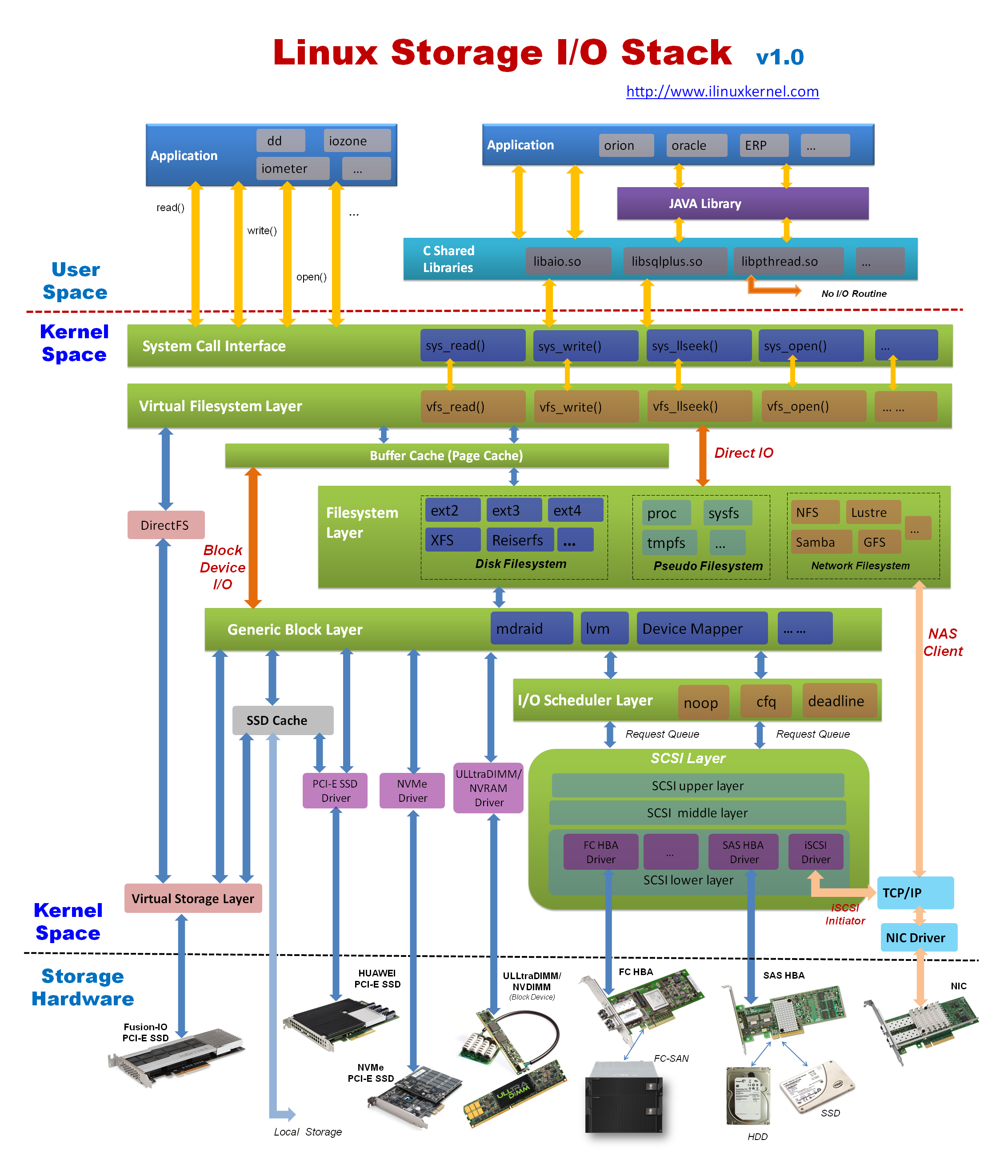
Linux I/O体系七层:
VFS
适配各种文件系统,对外提供统一API
磁盘:EXT,XFS …
网络:NFS, CIFS …
特殊:/proc,裸设备
磁盘缓存
磁盘数据驻留 RAM
映射层
确定数据在物理设备上的位置
通用块层
绝大多数I/O操作是跟块设备打交道
下层对接各种不同属性的块设备,对上提供统一的Block IO请求标准
I/O调度层
管理块设备的请求队列,有利于减少磁盘寻址时间,提高全局吞吐量
大多数块设备都是磁盘设备
根据设备及应用特点设置不同的调度器
块设备驱动
设备操作接口
物理硬盘
通信异常
不可用、延时、丢失
网络分区(脑裂)
系统分化出两个网络组,组内都正常通讯,但组间通讯被阻隔
三态
成功,失败和超时时(请求者无法判断当前请求是否成功处理)
节点故障
宕机,僵死,器件损坏等
保证共享资源一致性
实现事务隔离性
会出现死锁(锁是逐步获得的);锁定粒度最小,发生锁冲突的概率最低,并发度也最高存储引擎各自实现锁机制,server层不感知存储引擎的锁实现
共享锁(S)
排他锁(X)
意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁
意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁
允许行锁和表锁共存,实现多粒度锁机制
事务执行过程中,使用两阶段锁协议:
随时都可以执行锁定,InnoDB会根据隔离级别在需要的时候自动加锁
锁只有在执行commit或者rollback的时候才会释放,并且所有的锁都是在 ``同一时刻` 被释放
|
|
|
|
更新时,为防止发生冲突,需要这样操作
|
|
失败后重试或回滚
直接调用数据库的相关语句
悲观锁涉及的另外两个锁概念:共享锁与排它锁
共享锁(S):
|
|
确保自己查到的数据没有被其他的事务正在修改,也就是说确保查到的数据是最新的数据,并且不允许其他人来修改数据(获取数据上的排他锁)
自己不一定能够修改数据,因为有可能其他的事务也对这些数据 使用了 in share mode 的方式上了 S 锁
当前事务对读锁进行修改操作,很可能会造成死锁
|
|
| Transaction A | Transaction B |
|---|---|
| set autocommit=0;select * from innodb_lock where id=1 lock in share mode; | set autocommit=0;select * from innodb_lock where id=1 lock in share mode; |
| update innodb_lock set v=2 where id=1; 等待 |
|
| 等待 | update innodb_lock set v=2 where id=1; Deadlock found when trying to get lock; try restarting transaction |
| Affected rows: 1 |
排他锁(X):
|
|
自己查到的数据确保是最新数据,并且查到后的数据只允许自己来修改
一是内存爆了要用 LRU、LFU、FIFO 清理,否则磁盘SWAP,性能急剧下降
二是超时键过期要删除,用主动或惰性的方法
定时过期:
每个设置过expire时间的key都要创建一个定时器,到期立即清除
该策略可以立即清除过期的数据,对内存很友好
但占用大量CPU资源处理过期数据,从而影响响应时间和吞吐量
惰性过期:
访问key才会判断该key是否已过期,过期则清除
该策略可最大化节省CPU资源,却对内存非常不友好
极端情况可能出现大量过期key没有再次被访问,而不会被清除,占用大量内存
定期过期:
每隔一定的时间,扫描一定数量expires字典中一定数量的key,并清除其中已过期的key
该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可在不同情况下使CPU和内存资源达到最优的平衡效果
(expires字典,key指向键的指针,value是该键的毫秒精度UNIX时间戳)
Redis同时使用惰性过期和定期过期两种